15 Other Models
\[ \newcommand{\tr}{\mathrm{tr}} \newcommand{\rank}{\mathrm{rank}} \newcommand{\plim}{\operatornamewithlimits{plim}} \newcommand{\diag}{\mathrm{diag}} \newcommand{\bm}[1]{\boldsymbol{\mathbf{#1}}} \newcommand{\Var}{\mathrm{Var}} \newcommand{\Exp}{\mathrm{E}} \newcommand{\Cov}{\mathrm{Cov}} \newcommand\given[1][]{\:#1\vert\:} \newcommand{\irow}[1]{% \begin{pmatrix}#1\end{pmatrix} } \]
15.0.1 Required packages
15.0.2 Session info
R version 4.6.0 (2026-04-24 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26200)
Matrix products: default
LAPACK version 3.12.1
locale:
[1] LC_COLLATE=German_Germany.utf8 LC_CTYPE=German_Germany.utf8
[3] LC_MONETARY=German_Germany.utf8 LC_NUMERIC=C
[5] LC_TIME=German_Germany.utf8
time zone: Europe/Berlin
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods
[7] base
other attached packages:
[1] viridis_0.6.5 viridisLite_0.4.3 tmap_4.4
[4] ggplot2_4.0.3 spatialreg_1.4-3 Matrix_1.7-5
[7] spdep_1.4-2 spData_2.3.5 mapview_2.11.4
[10] GWmodel_2.4-1 Rcpp_1.1.1-1.1 sp_2.2-1
[13] robustbase_0.99-7 sf_1.1-1
loaded via a namespace (and not attached):
[1] tidyselect_1.2.1 dplyr_1.2.1
[3] farver_2.1.2 S7_0.2.2
[5] leaflegend_1.2.8 fastmap_1.2.0
[7] leaflet_2.2.3 TH.data_1.1-5
[9] XML_3.99-0.23 digest_0.6.39
[11] lifecycle_1.0.5 LearnBayes_2.15.2
[13] survival_3.8-6 terra_1.9-27
[15] magrittr_2.0.5 compiler_4.6.0
[17] rlang_1.2.0 tools_4.6.0
[19] data.table_1.18.4 knitr_1.51
[21] FNN_1.1.4.1 htmlwidgets_1.6.4
[23] classInt_0.4-11 RColorBrewer_1.1-3
[25] abind_1.4-8 multcomp_1.4-30
[27] KernSmooth_2.23-26 withr_3.0.2
[29] leafsync_0.1.0 grid_4.6.0
[31] stats4_4.6.0 xts_0.14.2
[33] cols4all_0.10 colorspace_2.1-2
[35] e1071_1.7-17 leafem_0.2.5
[37] spacesXYZ_1.6-0 scales_1.4.0
[39] MASS_7.3-65 cli_3.6.6
[41] mvtnorm_1.3-7 rmarkdown_2.31
[43] intervals_0.15.5 generics_0.1.4
[45] otel_0.2.0 rstudioapi_0.18.0
[47] tmaptools_3.3 DBI_1.3.0
[49] proxy_0.4-29 stars_0.7-2
[51] splines_4.6.0 parallel_4.6.0
[53] s2_1.1.11 base64enc_0.1-6
[55] marginaleffects_0.32.0 vctrs_0.7.3
[57] boot_1.3-32 sandwich_3.1-1
[59] jsonlite_2.0.0 crosstalk_1.2.2
[61] maptiles_0.11.0 units_1.0-1
[63] lwgeom_0.2-16 glue_1.8.1
[65] DEoptimR_1.2-0 codetools_0.2-20
[67] gtable_0.3.6 deldir_2.0-4
[69] raster_3.6-32 tibble_3.3.1
[71] logger_0.4.2 pillar_1.11.1
[73] htmltools_0.5.9 satellite_1.0.6
[75] R6_2.6.1 microbenchmark_1.5.0
[77] wk_0.9.5 evaluate_1.0.5
[79] lattice_0.22-9 png_0.1-9
[81] backports_1.5.1 class_7.3-23
[83] gridExtra_2.3 coda_0.19-4.1
[85] nlme_3.1-169 spacetime_1.3-3
[87] xfun_0.57 zoo_1.8-15
[89] pkgconfig_2.0.3 15.0.3 Reload data from pervious session
load("_data/msoa2_spatial.RData")15.1 Geographically weighted regression
Does the relation between \(y\) and \(x\) vary depending on the region we are looking at? With geographically weighted regressions (GWR), we can exploit the spatial heterogeneity in relations / coefficients.
GWR (Brunsdon et al. 1996; Gollini et al. 2015) is mainly an explorative tool for spatial data analysis in which we estimate an equation at different geographical points. For \(L\) given locations across London, we receive \(L\) different coefficients.
\[ \begin{split} \hat{\bm \beta}_l=& ({\bm X}^\intercal{\bm M}_l{\bm X})^{-1}{\bm X}^\intercal{\bm M}_l{\bm Y}, \end{split} \]
The \(N \times N\) matrix \({\bm M}_l\) defines the weights at each local point \(l\), assigning higher weights to closer units. The local weights are determined by a kernel density function with a pre-determined bandwidth \(b\) around each point (either a fixed distance or an adaptive k nearest neighbours bandwidth). Models are estimated via gwr.basic() or gwr.robust() of the GWmodel package.
Adaptive bandwidth: 615 CV score: 117.989
Adaptive bandwidth: 388 CV score: 107.5287
Adaptive bandwidth: 247 CV score: 89.99347
Adaptive bandwidth: 160 CV score: 76.23795
Adaptive bandwidth: 106 CV score: 66.39574
Adaptive bandwidth: 73 CV score: 62.89816
Adaptive bandwidth: 52 CV score: 59.46008
Adaptive bandwidth: 39 CV score: 56.70472
Adaptive bandwidth: 31 CV score: 54.97107
Adaptive bandwidth: 26 CV score: 53.27627
Adaptive bandwidth: 23 CV score: 54.23635
Adaptive bandwidth: 28 CV score: 54.47944
Adaptive bandwidth: 25 CV score: 52.5378
Adaptive bandwidth: 24 CV score: 53.74594
Adaptive bandwidth: 25 CV score: 52.5378 hv_1.bw[1] 25 ***********************************************************************
* Package GWmodel *
***********************************************************************
Program starts at: 2026-07-02 12:18:07.969916
Call:
gwr.basic(formula = formula, data = data, bw = bw, kernel = kernel,
adaptive = adaptive, p = p, theta = theta, longlat = longlat,
dMat = dMat, F123.test = F123.test, cv = T, W.vect = W.vect,
parallel.method = parallel.method, parallel.arg = parallel.arg)
Dependent (y) variable: med_house_price
Independent variables: no2 POPDEN pubs_count
Number of data points: 983
***********************************************************************
* Results of Global Regression *
***********************************************************************
Call:
lm(formula = formula, data = data)
Residuals:
Min 1Q Median 3Q Max
-0.90930 -0.24801 -0.05018 0.20925 1.49660
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 10.630835 0.194980 54.523 < 2e-16 ***
log(no2) 0.716116 0.074916 9.559 < 2e-16 ***
log(POPDEN) -0.111104 0.023101 -4.809 1.75e-06 ***
pubs_count 0.008513 0.004209 2.023 0.0434 *
---Significance stars
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.359 on 979 degrees of freedom
Multiple R-squared: 0.1177
Adjusted R-squared: 0.115
F-statistic: 43.55 on 3 and 979 DF, p-value: < 2.2e-16
***Extra Diagnostic information
Residual sum of squares: 126.1498
Sigma(hat): 0.3585988
AIC: 781.3976
AICc: 781.459
BIC: -142.6963
***********************************************************************
* Results of Geographically Weighted Regression *
***********************************************************************
*********************Model calibration information*********************
Kernel function: boxcar
Adaptive bandwidth: 25 (number of nearest neighbours)
Regression points: the same locations as observations are used.
Distance metric: Euclidean distance metric is used.
****************Summary of GWR coefficient estimates:******************
Min. 1st Qu. Median 3rd Qu. Max.
Intercept -5.4436033 10.0869061 13.1177690 15.5252567 26.8582
log(no2) -4.0174929 -0.7502331 0.0833824 1.0580475 6.2823
log(POPDEN) -0.8610728 -0.3139087 -0.1368702 -0.0200140 0.4031
pubs_count -0.3421595 -0.0252434 -0.0034784 0.0192272 0.2222
************************Diagnostic information*************************
Number of data points: 983
Effective number of parameters (2trace(S) - trace(S'S)): 136.1695
Effective degrees of freedom (n-2trace(S) + trace(S'S)): 846.8305
AICc (GWR book, Fotheringham, et al. 2002, p. 61, eq 2.33): -133.0433
AIC (GWR book, Fotheringham, et al. 2002,GWR p. 96, eq. 4.22): -316.0801
BIC (GWR book, Fotheringham, et al. 2002,GWR p. 61, eq. 2.34): -496.9587
Residual sum of squares: 36.33063
R-square value: 0.7459107
Adjusted R-square value: 0.7050051
***********************************************************************
Program stops at: 2026-07-02 12:18:20.281543 The results give a range of coefficients for different locations. Let’s map those individual coefficients.
# Spatial object
gwr.spdf <- st_as_sf(hv_1.gwr$SDF)
gwr.spdf <- st_make_valid(gwr.spdf)
# Map
tmap_mode("view")ℹ tmap modes "plot" - "view"
ℹ toggle with `tmap::ttm()`mp2 <- ggplot(data = gwr.spdf) +
geom_sf(aes(fill = `log(POPDEN)`), color = "grey92", size = 0.1) +
scale_fill_viridis_c(
name = "Coefficient",
option = "C",
direction = -1,
na.value = "grey90"
) +
labs(title = "Coefficient of log population density") +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 16),
legend.title = element_text(size = 10),
legend.text = element_text(size = 8),
legend.background = element_rect(fill = "white", color = "black"),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank()
)
mp2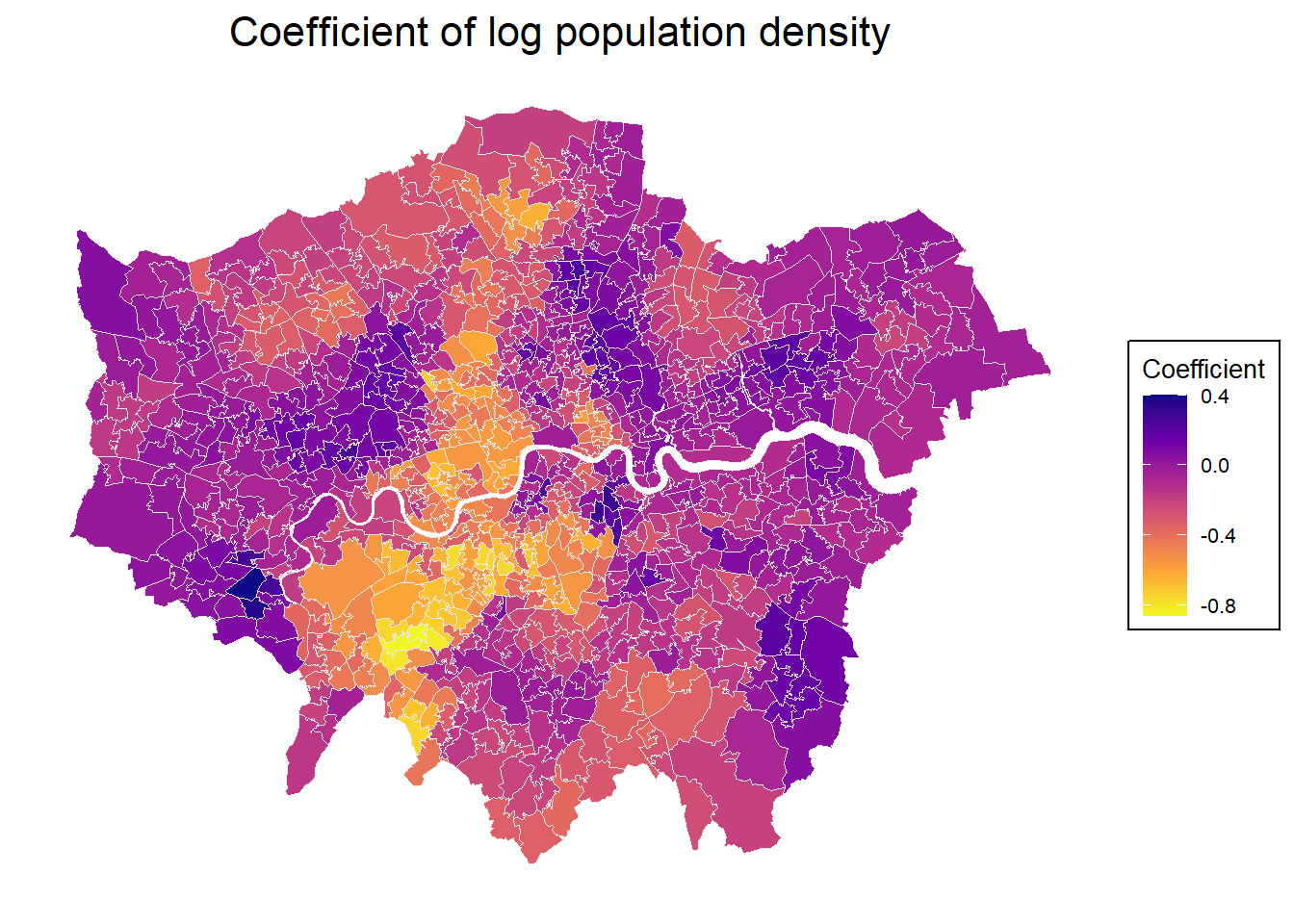
Just from looking at the map, there may be a connection with the undergrpund network - the effect of population density on house values seems to be stronger / more positive where underground connection is weaker?!
15.2 Non-Linear Models
Models with endogenous regressors (SAR)
In the literature: mostly spatial probit considered
Spatial logit rather uncommon (non normally distributed errors)
Issues with non-linear spatial models
Estimation: with dependent observations, we need to maximize one \(n\)-dimensional (log-)likelihood instead of a product of \(n\) independent distributions
Estimation challenging and computationally intense
Hard to interpret due to non-linear effects in non-linear models
Elhorst et al. (2017), Franzese et al. (2016)
15.2.1 Problem with non-linear models
Spatial-SAR-Probit \[ {\bm y^\star}=\rho{\bm W}{\bm y^\star}+{\bm X}{\bm \beta}+ {\bm \varepsilon} \\ y_i = \{1 \text{ if } y_i^\star > 0; 0 \text{ if } y_i^\star \leq 0 \} \nonumber \]
or in reduced form:
\[ {\bm y^\star}=(\bm I - \rho{\bm W})^{-1}{\bm X}{\bm \beta} + \bm u \text{, } \bm u = (\bm I - \rho{\bm W})^{-1}{\bm \varepsilon},\\ \text{with } \bm u \sim MVN(0, (\bm I - \rho{\bm W})^\intercal (\bm I - \rho{\bm W})^{-1}) \nonumber \]
Probability \(\bm y^\star\) is a latent variable, not observed
We only observe binary outcome \(y_i\)
\(\Cov(y_i, y_j)\) is not the same as \(\Cov(y_i^\star, y_j^\star)\)
Error term is heteroskedastic and spatially correlated
Probability
\[ \mathrm{Prob}[{\bm y^\star}>0] = \mathrm{Prob}[(\bm I - \rho{\bm W})^{-1}{\bm X}{\bm \beta} + (\bm I - \rho{\bm W})^{-1}{\bm \varepsilon}] \\ = \mathrm{Prob}[(\bm I - \rho{\bm W})^{-1}{\bm \varepsilon} < (\bm I - \rho{\bm W})^{-1}{\bm X}{\bm \beta}] \nonumber \]
or in using the observed outcome:\[ \mathrm{Prob}[\bm y_i=1 | \bm X] = \mathrm{Prob}\big[u_i < [(\bm I - \rho{\bm W})^{-1}{\bm X}{\bm \beta}]_i\big] \\ = \bm \phi\{[(\bm I - \rho{\bm W})^{-1}{\bm X}{\bm \beta}]_i / \sigma_{ui}\} \]
\(\bm \phi\{\}\) is an n-dimensional cumulative-normal distribution
\(\sigma_{ui}\) equals \((\bm I - \rho{\bm W})^\intercal (\bm I - \rho{\bm W})^{-1})_{ii}\), not constant
no analytical solution
15.2.2 Estimation
Estimation methods for Spatial-SAR Probit / Logit
Expectation Maximization (McMillen 1992).
(Linearized) Generalized Methods of Moments (Klier and McMillen 2008).
Recursive Importance Sampling (Beron and Vijverberg 2004).
Maximum Simulated Likelihood RIS (Franzese et al. 2016)
Bayesian approach with Markov Chain Monte Carlo simulations (LeSage and Pace 2009): R package
spatialprobit
Note that it can be hard to interpret the results. As in the linear case, it is necessary to compute the impacts. However, the `marginal’ effects may vary with values of the independent variables and the location (Lacombe and LeSage 2018).
15.2.3 Suggestion
If necessary, I would recommend using spatialprobit relying on Bayesian MCMC (set high ndraw and burn-in, e.g. 7500 and 2500).
There is an alternative package ProbitSpatial relying on maximisation of the approximate likelihood function. I haven’t used the package but it’s supposed to be computationally efficient for large data.
So far, no `best practice’ guide
No systematic comparison of estimation methods
Also SAR Probit/Logit need impact estimates.
spatialprobitandProbitSpatialprovide fucntions for impact measures
Work-around: If the specification is theoretical plausible, using SLX probit / logit might be a practical solution!