1 Refresher
Required packages
Session info
R version 4.6.0 (2026-04-24 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26200)
Matrix products: default
LAPACK version 3.12.1
locale:
[1] LC_COLLATE=German_Germany.utf8 LC_CTYPE=German_Germany.utf8
[3] LC_MONETARY=German_Germany.utf8 LC_NUMERIC=C
[5] LC_TIME=German_Germany.utf8
time zone: Europe/Berlin
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods
[7] base
other attached packages:
[1] texreg_1.39.5 tidyr_1.3.2 osmdata_0.3.0
[4] dplyr_1.2.1 rnaturalearth_1.2.0 nngeo_0.4.8
[7] mapview_2.11.4 gstat_2.1-6 sf_1.1-1
loaded via a namespace (and not attached):
[1] generics_0.1.4 class_7.3-23 KernSmooth_2.23-26
[4] lattice_0.22-9 digest_0.6.39 magrittr_2.0.5
[7] evaluate_1.0.5 grid_4.6.0 RColorBrewer_1.1-3
[10] fastmap_1.2.0 jsonlite_2.0.0 e1071_1.7-17
[13] DBI_1.3.0 httr_1.4.8 purrr_1.2.2
[16] crosstalk_1.2.2 scales_1.4.0 codetools_0.2-20
[19] cli_3.6.6 rlang_1.2.0 units_1.0-1
[22] intervals_0.15.5 base64enc_0.1-6 otel_0.2.0
[25] FNN_1.1.4.1 tools_4.6.0 raster_3.6-32
[28] spacetime_1.3-3 vctrs_0.7.3 R6_2.6.1
[31] png_0.1-9 stats4_4.6.0 zoo_1.8-15
[34] proxy_0.4-29 lifecycle_1.0.5 classInt_0.4-11
[37] leaflet_2.2.3 htmlwidgets_1.6.4 pkgconfig_2.0.3
[40] pillar_1.11.1 terra_1.9-27 glue_1.8.1
[43] data.table_1.18.4 Rcpp_1.1.1-1.1 tidyselect_1.2.1
[46] tibble_3.3.1 xfun_0.57 rstudioapi_0.18.0
[49] knitr_1.51 farver_2.1.2 htmltools_0.5.9
[52] rmarkdown_2.31 leafem_0.2.5 xts_0.14.2
[55] satellite_1.0.6 compiler_4.6.0 sp_2.2-1 1.1 Packages
Please make sure that you have installed the following packages:
pks <- c("dplyr",
"gstat",
"mapview",
"nngeo",
"nomisr",
"osmdata",
"rnaturalearth",
"sf",
"spatialreg",
"spdep",
"texreg",
"tidyr",
"tmap",
"viridisLite")The most important package is sf: Simple Features for R. users are strongly encouraged to install the sf binary packages from CRAN. If that does not work, please have a look at the installation instructions. It requires software packages GEOS, GDAL and PROJ.
1.2 Coordinates
In general, spatial data is structured like conventional/tidy data (e.g. data.frames, matrices), but has one additional dimension: every observation is linked to some sort of geo-spatial information. Most common types of spatial information are:
Points (one coordinate pair)
Lines (two coordinate pairs)
Polygons (at least three coordinate pairs)
Regular grids (one coordinate pair for centroid + raster / grid size)
1.2.1 Coordinate reference system (CRS)
In its raw form, a pair of coordinates consists of two numerical values. For instance, the pair c(51.752595, -1.262801) describes the location of Nuffield College in Oxford (one point). The fist number represents the latitude (north-south direction), the second number is the longitude (west-east direction), both are in decimal degrees.
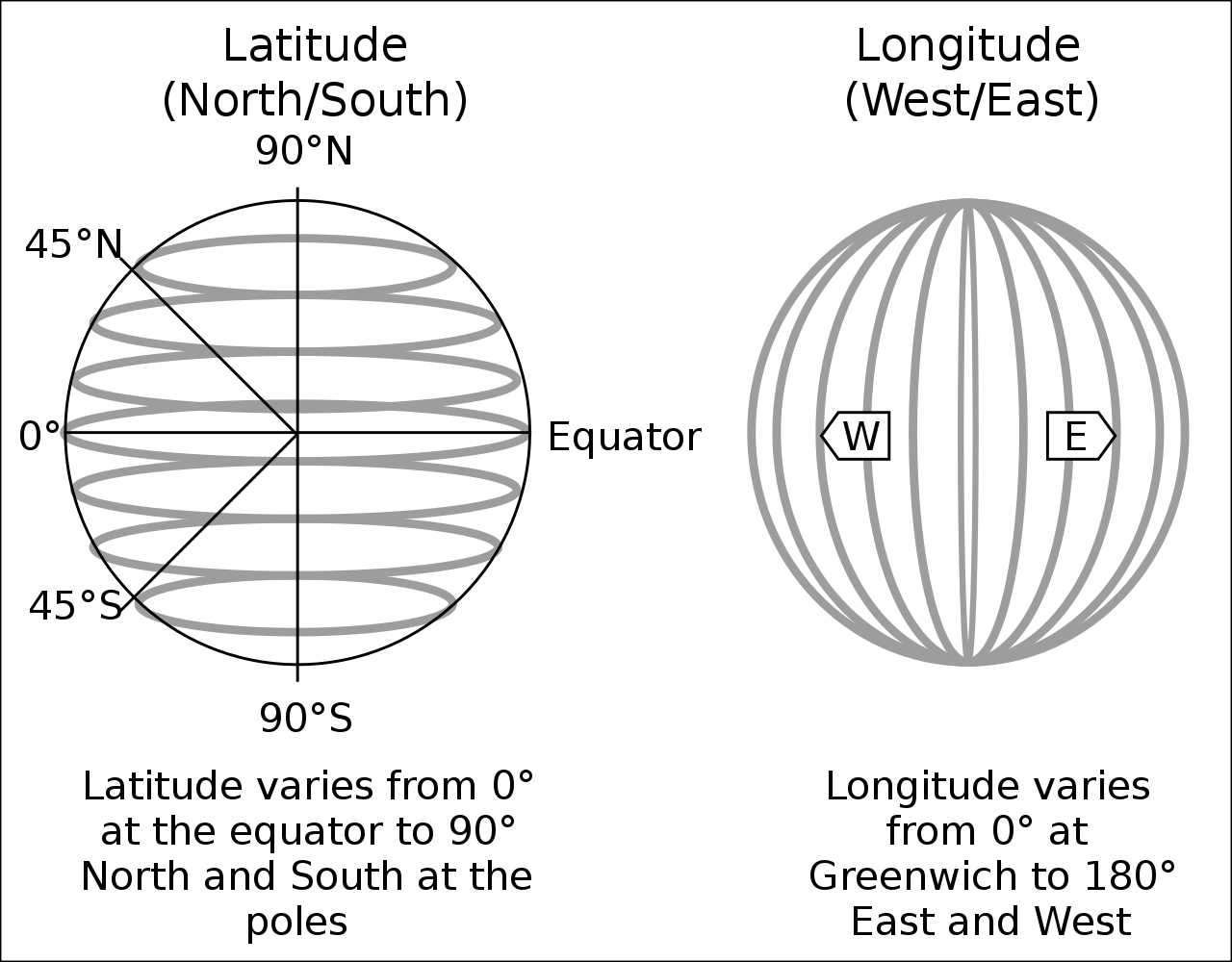
However, we need to specify a reference point for latitudes and longitudes (in the Figure above: equator and Greenwich). For instance, the pair of coordinates above comes from Google Maps which returns GPS coordinates in ‘WGS 84’ (EPSG:4326).
# Coordinate pairs of two locations
coords1 <- c(51.752595, -1.262801)
coords2 <- c(51.753237, -1.253904)
coords <- rbind(coords1, coords2)
# Conventional data frame
nuffield.df <- data.frame(name = c("Nuffield College", "Radcliffe Camera"),
address = c("New Road", "Radcliffe Sq"),
lat = coords[,1], lon = coords[,2])
head(nuffield.df) name address lat lon
coords1 Nuffield College New Road 51.75259 -1.262801
coords2 Radcliffe Camera Radcliffe Sq 51.75324 -1.253904# Combine to spatial data frame
nuffield.spdf <- st_as_sf(nuffield.df,
coords = c("lon", "lat"), # Order is important
crs = 4326) # EPSG number of CRS
# Map
mapview(nuffield.spdf, zcol = "name")1.2.2 Projected CRS
However, different data providers use different CRS. For instance, spatial data in the UK usually uses ‘OSGB 1936 / British National Grid’ (EPSG:27700). Here, coordinates are in meters, and projected onto a planar 2D space.
There are a lot of different CRS projections, and different national statistics offices provide data in different projections. Data providers usually specify which reference system they use. This is important as using the correct reference system and projection is crucial for plotting and manipulating spatial data.
If you do not know the correct CRS, try starting with a standards CRS like EPSG:4326 if you have decimal degree like coordinates. If it looks like projected coordinates, try searching for the country or region in CRS libraries like https://epsg.io/. However, you must check if the projected coordinates match their real location, e.g. using mapview().
1.2.3 Why different projections?
By now, (most) people agree that the earth is not flat. So, to plot data on a 2D planar surface and to perform certain operations on a planar world, we need to make some re-projections. This is actually difficult. See for example: Why all maps are wrong. Depending on where we are, different re-projections of our data (globe in this case) might work better than others.
world <- ne_countries(scale = "medium", returnclass = "sf")
class(world)[1] "sf" "data.frame"st_crs(world)Coordinate Reference System:
User input: WGS 84
wkt:
GEOGCRS["WGS 84",
DATUM["World Geodetic System 1984",
ELLIPSOID["WGS 84",6378137,298.257223563,
LENGTHUNIT["metre",1]]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
CS[ellipsoidal,2],
AXIS["latitude",north,
ORDER[1],
ANGLEUNIT["degree",0.0174532925199433]],
AXIS["longitude",east,
ORDER[2],
ANGLEUNIT["degree",0.0174532925199433]],
ID["EPSG",4326]]# Extract a country and plot in current CRS (WGS84)
ger.spdf <- world[world$name == "Germany", ]
plot(st_geometry(ger.spdf))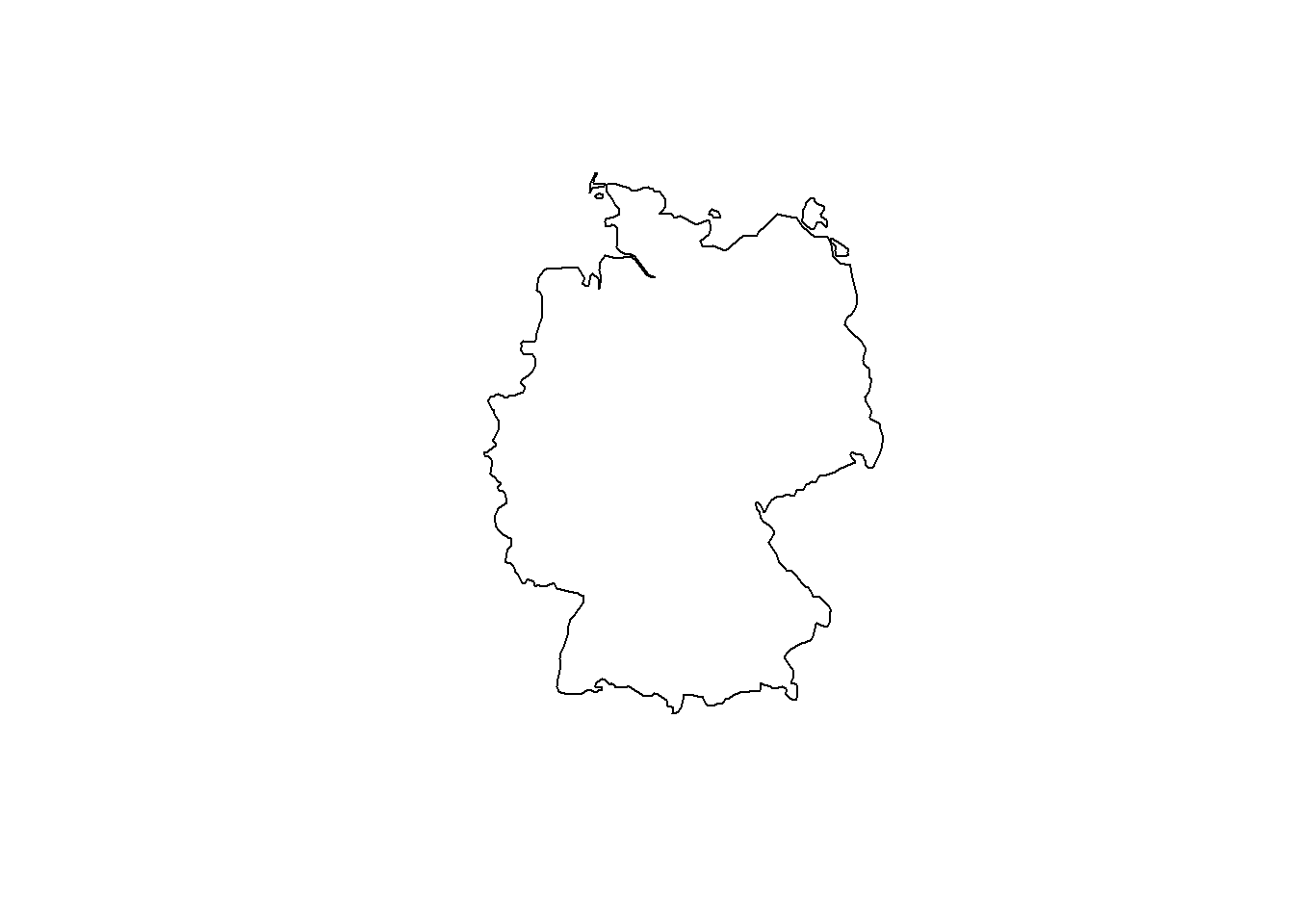
# Now, let's transform Germany into a CRS optimized for Iceland
ger_rep.spdf <- st_transform(ger.spdf, crs = 5325)
plot(st_geometry(ger_rep.spdf))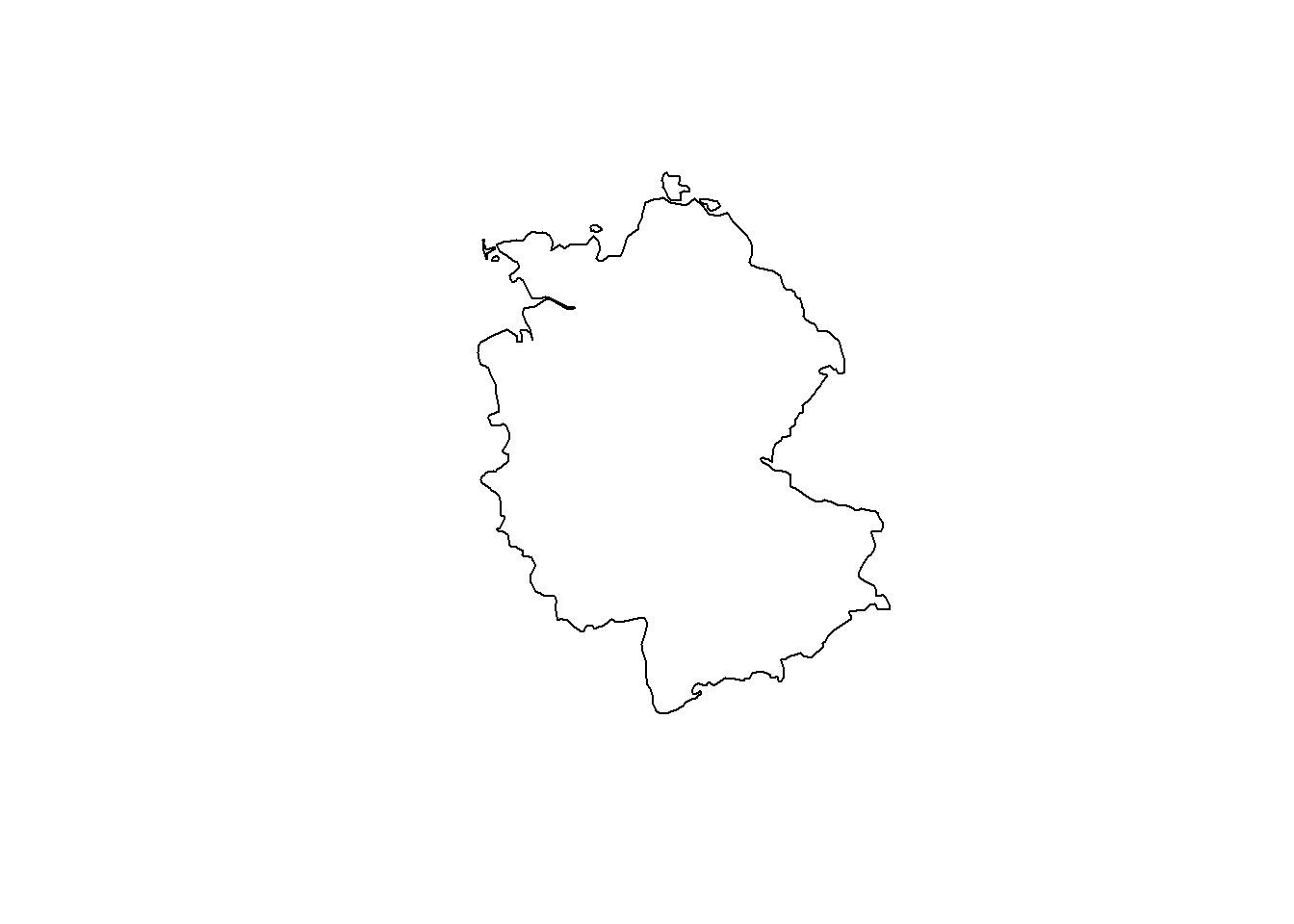
Depending on the angle, a 2D projection of the earth looks different. It is important to choose a suitable projection for the available spatial data. For more information on CRS and re-projection, see e.g. Lovelace et al. (2019) or Stefan Jünger & Anne-Kathrin Stroppe’s GESIS workshop materials.
1.3 Importing some real world data
sf imports many of the most common spatial data files, like geojson, gpkg, or shp.
1.3.1 London shapefile (polygon)
Let’s get some administrative boundaries for London from the London Datastore. We use the sf package and its funtion st_read() to import the data.
# Create subdir (all data withh be stored in "_data")
dn <- "_data"
ifelse(dir.exists(dn), "Exists", dir.create(dn))
# Download zip file and unzip
tmpf <- tempfile()
boundary.link <- "https://data.london.gov.uk/download/statistical-gis-boundary-files-london/9ba8c833-6370-4b11-abdc-314aa020d5e0/statistical-gis-boundaries-london.zip"
download.file(boundary.link, tmpf)
unzip(zipfile = tmpf, exdir = paste0(dn))
unlink(tmpf)dn <- "_data"
# This is a shapefile
# We only need the MSOA layer for now
msoa.spdf <- st_read(dsn = paste0(dn, "/statistical-gis-boundaries-london/ESRI"),
layer = "MSOA_2011_London_gen_MHW" # Note: no file ending
)Reading layer `MSOA_2011_London_gen_MHW' from data source
`C:\work\Lehre\Geodata_Spatial_Regression\_data\statistical-gis-boundaries-london\ESRI'
using driver `ESRI Shapefile'
Simple feature collection with 983 features and 12 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 503574.2 ymin: 155850.8 xmax: 561956.7 ymax: 200933.6
Projected CRS: OSGB36 / British National GridThe object msoa.spdf is our spatial data.frame. It looks essentially like a conventional data.frame, but has some additional attributes and geo-graphical information stored with it. Most importantly, notice the column geometry, which contains a list of polygons. In most cases, we have one polygon for each line / observation.
head(msoa.spdf)Simple feature collection with 6 features and 12 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 530966.7 ymin: 180510.7 xmax: 551943.8 ymax: 191139
Projected CRS: OSGB36 / British National Grid
MSOA11CD MSOA11NM LAD11CD LAD11NM
1 E02000001 City of London 001 E09000001 City of London
2 E02000002 Barking and Dagenham 001 E09000002 Barking and Dagenham
3 E02000003 Barking and Dagenham 002 E09000002 Barking and Dagenham
4 E02000004 Barking and Dagenham 003 E09000002 Barking and Dagenham
5 E02000005 Barking and Dagenham 004 E09000002 Barking and Dagenham
6 E02000007 Barking and Dagenham 006 E09000002 Barking and Dagenham
RGN11CD RGN11NM USUALRES HHOLDRES COMESTRES POPDEN HHOLDS
1 E12000007 London 7375 7187 188 25.5 4385
2 E12000007 London 6775 6724 51 31.3 2713
3 E12000007 London 10045 10033 12 46.9 3834
4 E12000007 London 6182 5937 245 24.8 2318
5 E12000007 London 8562 8562 0 72.1 3183
6 E12000007 London 8791 8672 119 50.6 3441
AVHHOLDSZ geometry
1 1.6 MULTIPOLYGON (((531667.6 18...
2 2.5 MULTIPOLYGON (((548881.6 19...
3 2.6 MULTIPOLYGON (((549102.4 18...
4 2.6 MULTIPOLYGON (((551550 1873...
5 2.7 MULTIPOLYGON (((549099.6 18...
6 2.5 MULTIPOLYGON (((549819.9 18...Shapefiles are still among the most common formats to store and transmit spatial data, despite them being inefficient (file size and file number).
However, sf reads everything spatial, such as geo.json, which usually is more efficient, but less common (but we’re getting there).
# Download file
ulez.link <- "https://data.london.gov.uk/download/ultra_low_emissions_zone/936d71d8-c5fc-40ad-a392-6bec86413b48/CentralUltraLowEmissionZone.geojson"
download.file(ulez.link, paste0(dn, "/ulez.json"))# Read geo.json
st_layers(paste0(dn, "/ulez.json"))Driver: GeoJSON
Available layers:
layer_name geometry_type features fields
1 CentralUltraLowEmissionZone Multi Polygon 1 4
crs_name
1 OSGB36 / British National Gridulez.spdf <- st_read(dsn = paste0(dn, "/ulez.json")) # here dsn is simply the fileReading layer `CentralUltraLowEmissionZone' from data source
`C:\work\Lehre\Geodata_Spatial_Regression\_data\ulez.json'
using driver `GeoJSON'
Simple feature collection with 1 feature and 4 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 527271.5 ymin: 178041.5 xmax: 533866.3 ymax: 183133.4
Projected CRS: OSGB36 / British National Gridhead(ulez.spdf)Simple feature collection with 1 feature and 4 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 527271.5 ymin: 178041.5 xmax: 533866.3 ymax: 183133.4
Projected CRS: OSGB36 / British National Grid
fid OBJECTID BOUNDARY Shape_Area geometry
1 1 1 CSS Area 21.37557 MULTIPOLYGON (((531562.7 18...Again, this looks like a conventional data.frame but has the additional column geometry containing the coordinates of each observation. st_geometry() returns only the geographic object and st_drop_geometry() only the data.frame without the coordinates. We can plot the object using mapview().
mapview(msoa.spdf, zcol = "POPDEN")1.3.2 Census API (admin units)
Now that we have some boundaries and shapes of spatial units in London, we can start looking for different data sources to populate the geometries.
A good source for demographic data is for instance the 2011 census. Below we use the nomis API to retrieve population data for London, See the Vignette for more information (Guest users are limited to 25,000 rows per query). Below is a wrapper to avoid some errors with sex and urban-rural cross-tabulation in some of the data.
### For larger request, register and set key
# Sys.setenv(NOMIS_API_KEY = "XXX")
# nomis_api_key(check_env = TRUE)
x <- nomis_data_info()
# Get London ids
london_ids <- msoa.spdf$MSOA11CD
### Get key statistics ids
# select requires tables (https://www.nomisweb.co.uk/sources/census_2011_ks)
# Let's get KS201EW (ethnic group), KS205EW (passport held), and KS402EW (housing tenure)
# Get internal ids
stats <- c("KS201EW", "KS402EW", "KS205EW")
oo <- which(grepl(paste(stats, collapse = "|"), x$name.value))
ksids <- x$id[oo]
ksids # This are the internal ids
### look at meta information
q <- nomis_overview(ksids[1])
head(q)
a <- nomis_get_metadata(id = ksids[1], concept = "GEOGRAPHY", type = "type")
a # TYPE297 is MSOA level
b <- nomis_get_metadata(id = ksids[1], concept = "MEASURES", type = "TYPE297")
b # 20100 is the measure of absolute numbers
### Query data in loop over the required statistics
for(i in ksids){
# Determin if data is divided by sex or urban-rural
nd <- nomis_get_metadata(id = i)
if("RURAL_URBAN" %in% nd$conceptref){
UR <- TRUE
}else{
UR <- FALSE
}
if("C_SEX" %in% nd$conceptref){
SEX <- TRUE
}else{
SEX <- FALSE
}
# make data request
if(UR == TRUE){
if(SEX == TRUE){
tmp_en <- nomis_get_data(id = i, time = "2011",
geography = london_ids, # replace with "TYPE297" for all MSOAs
measures = 20100, RURAL_URBAN = 0, C_SEX = 0)
}else{
tmp_en <- nomis_get_data(id = i, time = "2011",
geography = london_ids, # replace with "TYPE297" for all MSOAs
measures = 20100, RURAL_URBAN = 0)
}
}else{
if(SEX == TRUE){
tmp_en <- nomis_get_data(id = i, time = "2011",
geography = london_ids, # replace with "TYPE297" for all MSOAs
measures = 20100, C_SEX = 0)
}else{
tmp_en <- nomis_get_data(id = i, time = "2011",
geography = london_ids, # replace with "TYPE297" for all MSOAs
measures = 20100)
}
}
# Append (in case of different regions)
ks_tmp <- tmp_en
# Make lower case names
names(ks_tmp) <- tolower(names(ks_tmp))
names(ks_tmp)[names(ks_tmp) == "geography_code"] <- "msoa11"
names(ks_tmp)[names(ks_tmp) == "geography_name"] <- "name"
# replace weird cell codes
onlynum <- which(grepl("^[[:digit:]]+$", ks_tmp$cell_code))
if(length(onlynum) != 0){
code <- substr(ks_tmp$cell_code[-onlynum][1], 1, 7)
if(is.na(code)){
code <- i
}
ks_tmp$cell_code[onlynum] <- paste0(code, "_", ks_tmp$cell_code[onlynum])
}
# save codebook
ks_cb <- unique(ks_tmp[, c("date", "cell_type", "cell", "cell_code", "cell_name")])
### Reshape
ks_res <- tidyr::pivot_wider(ks_tmp, id_cols = c("msoa11", "name"),
names_from = "cell_code",
values_from = "obs_value")
### Merge
if(i == ksids[1]){
census_keystat.df <- ks_res
census_keystat_cb.df <- ks_cb
}else{
census_keystat.df <- merge(census_keystat.df, ks_res, by = c("msoa11", "name"), all = TRUE)
census_keystat_cb.df <- rbind(census_keystat_cb.df, ks_cb)
}
}
# Descriptions are saved in the codebook
save(census_keystat.df, file = "_data/Census_ckeystat.RData")
save(census_keystat_cb.df, file = "_data/Census_codebook.RData")Now, we have one file containing the geometries of MSOAs and one file with the census information on ethnic groups. Obviously, we can easily merge them together using the MSOA identifiers.
And we can, for instance, plot the spatial distribution of ethnic groups.
msoa.spdf$per_white <- msoa.spdf$KS201EW_100 / msoa.spdf$KS201EW0001 * 100
msoa.spdf$per_mixed <- msoa.spdf$KS201EW_200 / msoa.spdf$KS201EW0001 * 100
msoa.spdf$per_asian <- msoa.spdf$KS201EW_300 / msoa.spdf$KS201EW0001 * 100
msoa.spdf$per_black <- msoa.spdf$KS201EW_400 / msoa.spdf$KS201EW0001 * 100
msoa.spdf$per_other <- msoa.spdf$KS201EW_500 / msoa.spdf$KS201EW0001 * 100
mapview(msoa.spdf, zcol = "per_white")If you’re interested in more data sources, see for instance APIs for social scientists: A collaborative review by Paul C. Bauer, Camille Landesvatter, Lion Behrens. It’s a collection of several APIs for social sciences.
1.3.3 Gridded data
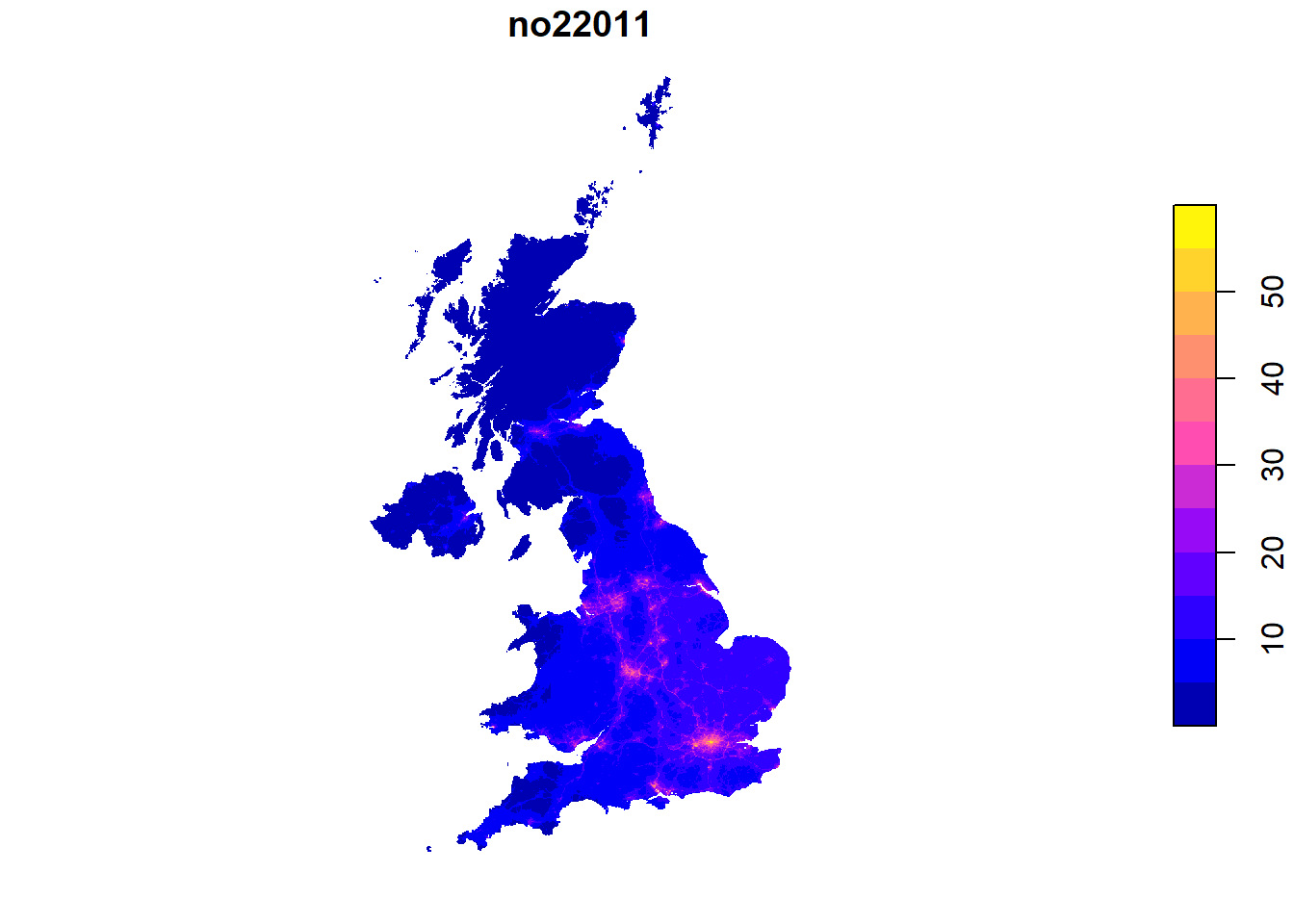
So far, we have queried data on administrative units. However, often data comes on other spatial scales. For instance, we might be interested in the amount of air pollution, which is provided on a regular grid across the UK from Defra.
# Download
pol.link <- "https://uk-air.defra.gov.uk/datastore/pcm/mapno22011.csv"
download.file(pol.link, paste0(dn, "/mapno22011.csv")) ukgridcode x y no22011
1 54291 460500 1221500 NA
2 54292 461500 1221500 NA
3 54294 463500 1221500 NA
4 54979 458500 1220500 NA
5 54980 459500 1220500 NA
6 54981 460500 1220500 NAThe data comes as point data with x and y as coordinates. We have to transform this into spatial data first. We first setup a spatial points object with st_as_sf. Subsequently, we transform the point coordinates into a regular grid. We use a buffer method st_buffer with “diameter”, and only one segment per quadrant (nQuadSegs). This gives us a 1x1km regular grid.
1.3.4 OpenStreetMap (points)
Another interesting data source is the OpenStreetMap API, which provides information about the geographical location of a serious of different indicators. Robin Lovelace provides a nice introduction to the osmdata API. Available features can be found on OSM wiki.
First we create a bounding box of where we want to query data. st_bbox() can be used to get bounding boxes of an existing spatial object (needs CRS = 4326). An alternative would be to use opq(bbox = 'greater london uk').
# bounding box of where we want to query data
q <- opq(bbox = st_bbox(st_transform(msoa.spdf, 4326)))And we want to get data for all pubs and bars which are within this bounding box.
# First build the query of location of pubs in London
osmq <- add_osm_feature(q, key = "amenity", value = "pub")
# And then query the data
pubs.osm <- osmdata_sf(osmq)Right now there are some results in polygons, some in points, and they overlap. Often, data from OSM needs some manual cleaning. Sometimes the same features are represented by different spatial objects (e.g. points + polygons).
# Make unique points / polygons
pubs.osm <- unique_osmdata(pubs.osm)
# Get points and polygons (there are barley any pubs as polygons, so we ignore them)
pubs.points <- pubs.osm$osm_points
pubs.polys <- pubs.osm$osm_multipolygons
# # Drop OSM file
# rm(pubs.osm); gc()
# Reduce to point object only
pubs.spdf <- pubs.points
# Reduce to a few variables
pubs.spdf <- pubs.spdf[, c("osm_id", "name", "addr:postcode", "diet:vegan")]Again, we can inspect the results with mapview.
# Reload (as I don't run the above here)
load("_data/osm_d.RData")mapview(st_geometry(pubs.spdf))Note that OSM is solely based on contribution by users, and the quality of OSM data varies. Usually data quality is better in larger cities, and better for more stable features (such as hospitals, train stations, highways) rahter than pubs or restaurants which regularly appear and disappear. However, data from London Datastore would indicate more pubs than what we find with OSM.
1.3.5 Save
We will store the created data to use them again in the next session.