14 Spatio-temporal models
\[ \newcommand{\tr}{\mathrm{tr}} \newcommand{\rank}{\mathrm{rank}} \newcommand{\plim}{\operatornamewithlimits{plim}} \newcommand{\diag}{\mathrm{diag}} \newcommand{\bm}[1]{\boldsymbol{\mathbf{#1}}} \newcommand{\Var}{\mathrm{Var}} \newcommand{\Exp}{\mathrm{E}} \newcommand{\Cov}{\mathrm{Cov}} \newcommand\given[1][]{\:#1\vert\:} \newcommand{\irow}[1]{% \begin{pmatrix}#1\end{pmatrix} } \]
Required packages
Session info
R version 4.6.0 (2026-04-24 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26200)
Matrix products: default
LAPACK version 3.12.1
locale:
[1] LC_COLLATE=German_Germany.utf8 LC_CTYPE=German_Germany.utf8
[3] LC_MONETARY=German_Germany.utf8 LC_NUMERIC=C
[5] LC_TIME=German_Germany.utf8
time zone: Europe/Berlin
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods
[7] base
other attached packages:
[1] SDPDmod_0.0.7 splm_1.6-5 plm_2.6-7
[4] viridisLite_0.4.3 tmap_4.4 spatialreg_1.4-3
[7] Matrix_1.7-5 spdep_1.4-2 spData_2.3.5
[10] mapview_2.11.4 sf_1.1-1
loaded via a namespace (and not attached):
[1] Rdpack_2.6.6 DBI_1.3.0
[3] deldir_2.0-4 tmaptools_3.3
[5] s2_1.1.11 logger_0.4.2
[7] sandwich_3.1-1 rlang_1.2.0
[9] magrittr_2.0.5 multcomp_1.4-30
[11] dreamerr_1.5.0 otel_0.2.0
[13] e1071_1.7-17 compiler_4.6.0
[15] png_0.1-9 stringr_1.6.0
[17] wk_0.9.5 fastmap_1.2.0
[19] backports_1.5.1 lwgeom_0.2-16
[21] leafem_0.2.5 rmarkdown_2.31
[23] spacesXYZ_1.6-0 miscTools_0.6-30
[25] xfun_0.57 satellite_1.0.6
[27] jsonlite_2.0.0 stringmagic_1.2.0
[29] collapse_2.1.7 terra_1.9-27
[31] parallel_4.6.0 LearnBayes_2.15.2
[33] R6_2.6.1 stringi_1.8.7
[35] RColorBrewer_1.1-3 boot_1.3-32
[37] lmtest_0.9-40 stars_0.7-2
[39] numDeriv_2016.8-1.1 Rcpp_1.1.1-1.1
[41] knitr_1.51 zoo_1.8-15
[43] base64enc_0.1-6 splines_4.6.0
[45] rstudioapi_0.18.0 abind_1.4-8
[47] maptiles_0.11.0 maxLik_1.5-2.2
[49] codetools_0.2-20 lattice_0.22-9
[51] leafsync_0.1.0 coda_0.19-4.1
[53] evaluate_1.0.5 marginaleffects_0.32.0
[55] survival_3.8-6 units_1.0-1
[57] proxy_0.4-29 fixest_0.14.1
[59] KernSmooth_2.23-26 stats4_4.6.0
[61] generics_0.1.4 sp_2.2-1
[63] scales_1.4.0 xtable_1.8-8
[65] class_7.3-23 glue_1.8.1
[67] tools_4.6.0 lfe_3.1.1
[69] leaflegend_1.2.8 data.table_1.18.4
[71] RSpectra_0.16-2 mvtnorm_1.3-7
[73] XML_3.99-0.23 dotCall64_1.2
[75] grid_4.6.0 rbibutils_2.4.1
[77] crosstalk_1.2.2 bdsmatrix_1.3-7
[79] colorspace_2.1-2 nlme_3.1-169
[81] cols4all_0.10 raster_3.6-32
[83] Formula_1.2-5 cli_3.6.6
[85] spam_2.11-4 digest_0.6.39
[87] classInt_0.4-11 TH.data_1.1-5
[89] htmlwidgets_1.6.4 farver_2.1.2
[91] htmltools_0.5.9 lifecycle_1.0.5
[93] leaflet_2.2.3 microbenchmark_1.5.0
[95] MASS_7.3-65 Elhorst (2014) provides a comprehensive introduction to spatial panel data methods. Article length introduction to spatial panel data models (FE and RE) can be found in Elhorst (2012), Millo and Piras (2012) and Croissant and Millo (2018). LeSage (2014) discusses Bayesian panel data methods.
Note that we will only discuss some basics here, as the complete econometrics of these models and their estimation strategy become insanely complicated (Lee and Yu 2010).
14.1 Static panel data models
The idea behind a static panel data with auto-regressive term is similar to the cross sectional situation (Millo and Piras 2012).
\[ {\bm y}= \rho(\bm I_T\otimes {\bm W_N}){\bm y}+{\bm X}{\bm \beta}+ {\bm u}. \]
where \(\otimes\) is the Kronecker product (block-wise multiplication).
\[ \begin{split} \underbrace{\underbrace{\bm I_T}_{T \times T} \otimes \underbrace{\bm W_N}_{N \times N}}_{NT \times NT}= \begin{pmatrix} 1 & 0 & \cdots & 0 \\ 0 & 1 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 1 \end{pmatrix} \left[\begin{array}{cccc} v_{1} w_{1} & v_{1} w_{2} & \cdots & v_{1} w_{m} \\ v_{2} w_{1} & v_{2} w_{2} & \cdots & v_{2} w_{m} \\ \vdots & \vdots & \ddots & \vdots \\ v_{n} w_{1} & v_{n} w_{2} & \cdots & v_{n} w_{m} \end{array}\right] =\\ \begin{pmatrix} \left[\begin{array}{cccc} v_{1} w_{1} & v_{1} w_{2} & \cdots & v_{1} w_{m} \\ v_{2} w_{1} & v_{2} w_{2} & \cdots & v_{2} w_{m} \\ \vdots & \vdots & \ddots & \vdots \\ v_{n} w_{1} & v_{n} w_{2} & \cdots & v_{n} w_{m} \end{array}\right] & 0 & \cdots & 0 \\ 0 & \left[\begin{array}{cccc} v_{1} w_{1} & v_{1} w_{2} & \cdots & v_{1} w_{m} \\ v_{2} w_{1} & v_{2} w_{2} & \cdots & v_{2} w_{m} \\ \vdots & \vdots & \ddots & \vdots \\ v_{n} w_{1} & v_{n} w_{2} & \cdots & v_{n} w_{m} \end{array}\right] & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \left[\begin{array}{cccc} v_{1} w_{1} & v_{1} w_{2} & \cdots & v_{1} w_{m} \\ v_{2} w_{1} & v_{2} w_{2} & \cdots & v_{2} w_{m} \\ \vdots & \vdots & \ddots & \vdots \\ v_{n} w_{1} & v_{n} w_{2} & \cdots & v_{n} w_{m} \end{array}\right] \end{pmatrix} \end{split} \]
Here we model only spatial dependence within each cross-section and multiply the same spatial weights matrix \(T\) times. Off block-diagonal elements are all zero. So there is no spatial dependence that goes across time.
The error term can be decomposed into two parts:
\[ {\bm u}= (\bm \iota_T \otimes {\bm I_N})\bm \mu+ {\bm \nu}, \]
where \(\bm \iota_T\) is a \(T \times 1\) vector of ones, \({\bm I_N}\) an \(N \times N\) identity matrix, \(\bm \mu\) is a vector of time-invariant individual specific effects (not spatially autocorrelated).
We could obviously extent the specification to allow for error correlation by specifying
\[ {\bm \nu}= \lambda(\bm I_T \otimes {\bm W_N})\bm \nu + {\bm \varepsilon}. \]
The individual effects can be treated as fixed or random.
Fixed Effects
In the FE model, the individual specific effects are treated as fixed. If we re-write the equation above, we derive at the well-know fixed effects formula with an additional spatial autoregressive term:
\[ {y_{it}}= \rho\sum_{j=1}^Nw_{ij}y_{jt} + \bm x_{it}\bm\beta + \mu_i + \nu_{it}, \] where \(\mu_i\) denote the individual-specific fixed effects.
As with the standard spatial lag model, we cannot rely on the OLS estimator because of the simultaneity problem. The coefficients are thus estimated by maximum likelihood (Elhorst 2014).
Random Effects
In the RE model, the individual specific effects are treated as components of the error \(\mu \sim \mathrm{IID}(o, \sigma_\mu^2)\). The model can then be written as
\[ \begin{split} {\bm y}= \rho(\bm I_T\otimes {\bm W_N}){\bm y}+{\bm X}{\bm \beta}+ {\bm u}, \\ {\bm u}= (\bm \iota_T \otimes {\bm I_N})\bm \mu+ [\bm I_T \otimes (\bm I_N - \lambda{\bm W_N})]^{-1} {\bm \varepsilon}. \end{split} \]
As with the conventional random effects model, we make the strong assumption that the unobserved individual effects are uncorrelated with the covariates \(\bm X\) in the model.
14.2 Dynamic panel data models
Relying on panel data and repeated measures over time, comes with an additional layer of dependence / autocorrelation between units. We have spatial dependence (with its three potential sources), and we have temporal/serial dependence within each unit over time.
A general dynamic model would account for all sources of potential dependence, including combinations (Elhorst 2012). The most general model can be written as:
\[ \begin{split} {\bm y_t}=& \tau \bm y_{t-1} + \rho(\bm I_T\otimes {\bm W_N}){\bm y}_t + \gamma(\bm I_T\otimes {\bm W_N}){\bm y_{t-1}}\\ &~+ {\bm X}{\bm \beta}+ (\bm I_T\otimes {\bm W_N}){\bm X}{\bm \theta}+ {\bm u}_t,\\ {\bm u_t}=& + (\bm \iota_T \otimes {\bm I_N})\bm \mu+ {\bm \nu_t},\\ {\bm \nu_t}=& \psi{\bm \nu}_{t-1} + \lambda(\bm I_T \otimes {\bm W_N})\bm \nu + {\bm \varepsilon}, \end{split} \]
Where \({\bm X}\) could further contain time-lagged covariates. Compared to the static spatial panel model, we have introduced temporal dependency in the outcome \(\tau \bm y_{t-1}\) and the spatially lagged outcome \(\gamma(\bm I_T\otimes {\bm W_N}){\bm y_{t-1}}\), and in the error term \(\psi{\bm \nu}_{t-1}\).
14.2.1 Impacts in spatial panel models
Note that similar to the distinction between local and global spillovers, we now have to distinguish between short-term and long-term effects. A change in \(\bm X_t\) no influences focal \(Y\) and neighbour’s \(Y\) but also contemporaneous \(Y\) and future \(Y\).
While the short-term effects are the known impacts
\[ \frac{\partial {\bm y}}{\partial {\bm x}_k} = ({\bm I}-\rho{\bm W_{NT}})^{-1}\left[\beta_k+{\bm W_{NT}}\theta_k\right]. \]
The long-term impacts, by contrast, additionally account for the effect multiplying through time
\[ \frac{\partial {\bm y}}{\partial {\bm x}_k} = [(1-\tau){\bm I}-(\rho+\gamma){\bm W_{NT}}]^{-1}\left[\beta_k+{\bm W_{NT}}\theta_k\right]. \]
For more information see Elhorst (2012).

14.3 Example: Local employment impacts of immigration
Fingleton et al. (2020): Estimating the local employment impacts of immigration: A dynamic spatial panel model. Urban Studies, 57(13), 2646–2662. https://doi.org/10.1177/0042098019887916
This paper highlights a number of important gaps in the UK evidence base on the employment impacts of immigration, namely: (1) the lack of research on the local impacts of immigration – existing studies only estimate the impact for the country as a whole; (2) the absence of long-term estimates – research has focused on relatively short time spans – there are no estimates of the impact over several decades, for example; (3) the tendency to ignore spatial dependence of employment which can bias the results and distort inference – there are no robust spatial econometric estimates we are aware of.
We illustrate our approach with an application to London and find that no migrant group has a statistically significant long-term negative effect on employment. EU migrants, however, are found to have a significant positive impact, which may have important implications for the Brexit debate. Our approach opens up a new avenue of inquiry into subnational variations in the impacts of immigration on employment.

14.4 Estimation in R
To estimate spatial panel models in R, we can use the splm package of Millo and Piras (2012).
We use a standard example with longitudinal data from the plm package here.
state year region pcap hwy water util pc
1 ALABAMA 1970 6 15032.67 7325.80 1655.68 6051.20 35793.80
2 ALABAMA 1971 6 15501.94 7525.94 1721.02 6254.98 37299.91
3 ALABAMA 1972 6 15972.41 7765.42 1764.75 6442.23 38670.30
4 ALABAMA 1973 6 16406.26 7907.66 1742.41 6756.19 40084.01
5 ALABAMA 1974 6 16762.67 8025.52 1734.85 7002.29 42057.31
6 ALABAMA 1975 6 17316.26 8158.23 1752.27 7405.76 43971.71
gsp emp unemp
1 28418 1010.5 4.7
2 29375 1021.9 5.2
3 31303 1072.3 4.7
4 33430 1135.5 3.9
5 33749 1169.8 5.5
6 33604 1155.4 7.7usaww[1:10, 1:10] ALABAMA ARIZONA ARKANSAS CALIFORNIA COLORADO
ALABAMA 0.0 0.0000000 0 0.0 0.0
ARIZONA 0.0 0.0000000 0 0.2 0.2
ARKANSAS 0.0 0.0000000 0 0.0 0.0
CALIFORNIA 0.0 0.3333333 0 0.0 0.0
COLORADO 0.0 0.1428571 0 0.0 0.0
CONNECTICUT 0.0 0.0000000 0 0.0 0.0
DELAWARE 0.0 0.0000000 0 0.0 0.0
FLORIDA 0.5 0.0000000 0 0.0 0.0
GEORGIA 0.2 0.0000000 0 0.0 0.0
IDAHO 0.0 0.0000000 0 0.0 0.0
CONNECTICUT DELAWARE FLORIDA GEORGIA IDAHO
ALABAMA 0 0 0.25 0.25 0
ARIZONA 0 0 0.00 0.00 0
ARKANSAS 0 0 0.00 0.00 0
CALIFORNIA 0 0 0.00 0.00 0
COLORADO 0 0 0.00 0.00 0
CONNECTICUT 0 0 0.00 0.00 0
DELAWARE 0 0 0.00 0.00 0
FLORIDA 0 0 0.00 0.50 0
GEORGIA 0 0 0.20 0.00 0
IDAHO 0 0 0.00 0.00 0Produc contains data on US States Production - a panel of 48 observations from 1970 to 1986. usaww is a spatial weights matrix of the 48 continental US States based on the queen contiguity relation.
Let start with an FE SEM model, using function spml() for maximum likelihood estimation of static spatial panel models.
# Gen listw object
usalw <- mat2listw(usaww, style = "W")
# Spec formula
fm <- log(gsp) ~ log(pcap) + log(pc) + log(emp) + unemp
### Esimate FE SEM model
semfe.mod <- spml(formula = fm, data = Produc,
index = c("state", "year"), # ID column
listw = usalw, # listw
model = "within", # one of c("within", "random", "pooling").
effect = "individual", # type of fixed effects
lag = FALSE, # spatila lg of Y
spatial.error = "b", # "b" (Baltagi), "kkp" (Kapoor, Kelejian and Prucha)
method = "eigen", # estimation method, for large data e.g. ("spam", "Matrix" or "LU")
na.action = na.fail, # handling of missings
zero.policy = NULL) # handling of missings
summary(semfe.mod)Spatial panel fixed effects error model
Call:
spml(formula = fm, data = Produc, index = c("state", "year"),
listw = usalw, na.action = na.fail, model = "within", effect = "individual",
lag = FALSE, spatial.error = "b", method = "eigen", zero.policy = NULL)
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-0.1247 -0.0238 -0.0035 0.0171 0.1882
Spatial error parameter:
Estimate Std. Error t-value Pr(>|t|)
rho 0.557401 0.033075 16.853 < 2.2e-16 ***
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
log(pcap) 0.0051438 0.0250109 0.2057 0.83705
log(pc) 0.2053026 0.0231427 8.8712 < 2e-16 ***
log(emp) 0.7822540 0.0278057 28.1328 < 2e-16 ***
unemp -0.0022317 0.0010709 -2.0839 0.03717 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1A RE SAR model, by contrast, can be estimated using the following options:
### Estimate an RE SAR model
sarre.mod <- spml(formula = fm, data = Produc,
index = c("state", "year"), # ID column
listw = usalw, # listw
model = "random", # one of c("within", "random", "pooling").
effect = "individual", # type of fixed effects
lag = TRUE, # spatila lg of Y
spatial.error = "none", # "b" (Baltagi), "kkp" (Kapoor, Kelejian and Prucha)
method = "eigen", # estimation method, for large data e.g. ("spam", "Matrix" or "LU")
na.action = na.fail, # handling of missings
zero.policy = NULL) # handling of missings
summary(sarre.mod)ML panel with spatial lag, random effects
Call:
spreml(formula = formula, data = data, index = index, w = listw2mat(listw),
w2 = listw2mat(listw2), lag = lag, errors = errors, cl = cl,
method = "eigen", zero.policy = ..2)
Residuals:
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.38 1.57 1.70 1.70 1.80 2.13
Error variance parameters:
Estimate Std. Error t-value Pr(>|t|)
phi 21.3175 8.2929 2.5706 0.01015 *
Spatial autoregressive coefficient:
Estimate Std. Error t-value Pr(>|t|)
lambda 0.161615 0.029042 5.5648 2.625e-08 ***
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
(Intercept) 1.65814987 0.15071855 11.0016 < 2.2e-16 ***
log(pcap) 0.01294505 0.02493997 0.5190 0.6037
log(pc) 0.22555375 0.02163422 10.4258 < 2.2e-16 ***
log(emp) 0.67081074 0.02642113 25.3892 < 2.2e-16 ***
unemp -0.00579716 0.00089175 -6.5009 7.984e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Note that Millo and Piras (2012) use a different notation, namely \(\lambda\) for lag dependence, and \(\rho\) for error dependence….
Again, we have to use an additional step to get impacts for SAR-like models.
Impact measures (lag, trace):
Direct Indirect Total
log(pcap) dy/dx 0.013028574 0.002411880 0.015440454
log(pc) dy/dx 0.227009032 0.042024438 0.269033470
log(emp) dy/dx 0.675138835 0.124983264 0.800122098
unemp dy/dx -0.005834562 -0.001080108 -0.006914669
========================================================
Simulation results ( variance matrix):
Direct:
Iterations = 1:200
Thinning interval = 1
Number of chains = 1
Sample size per chain = 200
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
log(pcap) dy/dx 0.015643 0.0253701 1.794e-03 1.794e-03
log(pc) dy/dx 0.226278 0.0210178 1.486e-03 1.279e-03
log(emp) dy/dx 0.674741 0.0246999 1.747e-03 1.747e-03
unemp dy/dx -0.005809 0.0008709 6.158e-05 6.158e-05
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
log(pcap) dy/dx -0.031095 -0.0001976 0.013964 0.031006 0.080600
log(pc) dy/dx 0.188363 0.2129714 0.227291 0.239634 0.268351
log(emp) dy/dx 0.626891 0.6609800 0.676090 0.690972 0.721911
unemp dy/dx -0.007316 -0.0064506 -0.005841 -0.005264 -0.004176
========================================================
Indirect:
Iterations = 1:200
Thinning interval = 1
Number of chains = 1
Sample size per chain = 200
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
log(pcap) dy/dx 0.002972 0.005048 3.570e-04 3.570e-04
log(pc) dy/dx 0.042893 0.010070 7.121e-04 7.476e-04
log(emp) dy/dx 0.127821 0.027824 1.967e-03 1.967e-03
unemp dy/dx -0.001103 0.000298 2.107e-05 2.034e-05
2. Quantiles for each variable:
2.5% 25% 50% 75%
log(pcap) dy/dx -0.005908 -4.279e-05 0.002609 0.0057705
log(pc) dy/dx 0.024594 3.584e-02 0.041603 0.0497254
log(emp) dy/dx 0.067864 1.089e-01 0.127996 0.1433225
unemp dy/dx -0.001688 -1.304e-03 -0.001086 -0.0008721
97.5%
log(pcap) dy/dx 0.0152746
log(pc) dy/dx 0.0634571
log(emp) dy/dx 0.1818456
unemp dy/dx -0.0005674
========================================================
Total:
Iterations = 1:200
Thinning interval = 1
Number of chains = 1
Sample size per chain = 200
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
log(pcap) dy/dx 0.018615 0.03032 2.144e-03 2.144e-03
log(pc) dy/dx 0.269170 0.02698 1.908e-03 1.908e-03
log(emp) dy/dx 0.802562 0.04072 2.880e-03 2.880e-03
unemp dy/dx -0.006912 0.00108 7.637e-05 6.108e-05
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
log(pcap) dy/dx -0.035392 -0.0002404 0.016605 0.037223 0.096683
log(pc) dy/dx 0.222280 0.2525594 0.266318 0.286184 0.322695
log(emp) dy/dx 0.726961 0.7746688 0.802641 0.828254 0.880532
unemp dy/dx -0.008892 -0.0076905 -0.006903 -0.006146 -0.004899There is an alternative by using the package SDPDmod by Rozeta Simonovska (see vignette).
### FE SAR model
sarfe.mod2 <- SDPDm(formula = fm,
data = Produc,
W = usaww,
index = c("state","year"), # ID
model = "sar", # on of c("sar","sdm"),
effect = "individual", # FE structure
dynamic = FALSE, # time lags of the dependet variable
LYtrans = TRUE) # Lee-Yu transformation (bias correction)
summary(sarfe.mod2)sar panel model with individual fixed effects
Call:
SDPDm(formula = fm, data = Produc, W = usaww, index = c("state",
"year"), model = "sar", effect = "individual", dynamic = FALSE,
LYtrans = TRUE)
Spatial autoregressive coefficient:
Estimate Std. Error t-value Pr(>|t|)
rho 0.27856 0.02400 11.607 < 2.2e-16 ***
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
log(pcap) -0.0468700 0.0262162 -1.7878 0.0738 .
log(pc) 0.1859579 0.0237252 7.8380 4.578e-15 ***
log(emp) 0.6230728 0.0305554 20.3916 < 2.2e-16 ***
unemp -0.0044701 0.0008917 -5.0130 5.359e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1And subsequently, we can calculate the impacts of the model.
# Impats
sarfe.mod2.imp <- impactsSDPDm(sarfe.mod2,
NSIM = 200, # N simulations
sd = 12345) # seed
summary(sarfe.mod2.imp)
Impact estimates for spatial (static) model
========================================================
Direct:
Estimate Std. Error t-value Pr(>|t|)
log(pcap) -0.04548734 0.02599122 -1.7501 0.0801 .
log(pc) 0.18811130 0.02383583 7.8920 2.975e-15 ***
log(emp) 0.63774644 0.03027064 21.0682 < 2.2e-16 ***
unemp -0.00459922 0.00089695 -5.1276 2.935e-07 ***
Indirect:
Estimate Std. Error t-value Pr(>|t|)
log(pcap) -0.01635496 0.00940025 -1.7398 0.08189 .
log(pc) 0.06724002 0.00990916 6.7856 1.156e-11 ***
log(emp) 0.22817291 0.02236760 10.2010 < 2.2e-16 ***
unemp -0.00164883 0.00037103 -4.4440 8.831e-06 ***
Total:
Estimate Std. Error t-value Pr(>|t|)
log(pcap) -0.0618423 0.0352523 -1.7543 0.07938 .
log(pc) 0.2553513 0.0313969 8.1330 4.188e-16 ***
log(emp) 0.8659194 0.0371907 23.2832 < 2.2e-16 ***
unemp -0.0062481 0.0012311 -5.0752 3.871e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Note: I did not manage to estimate a dynamic panel model with SDPDm.
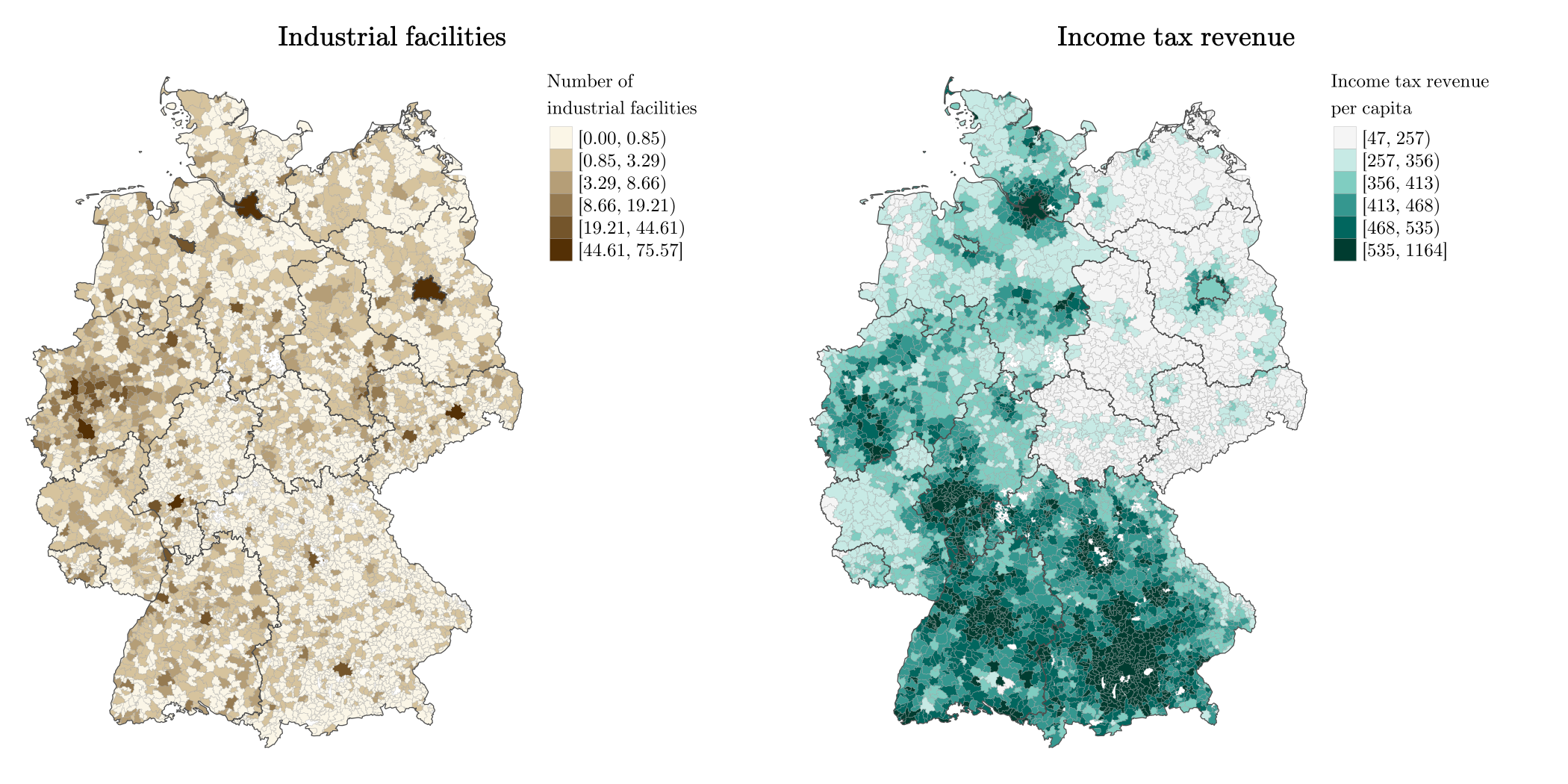
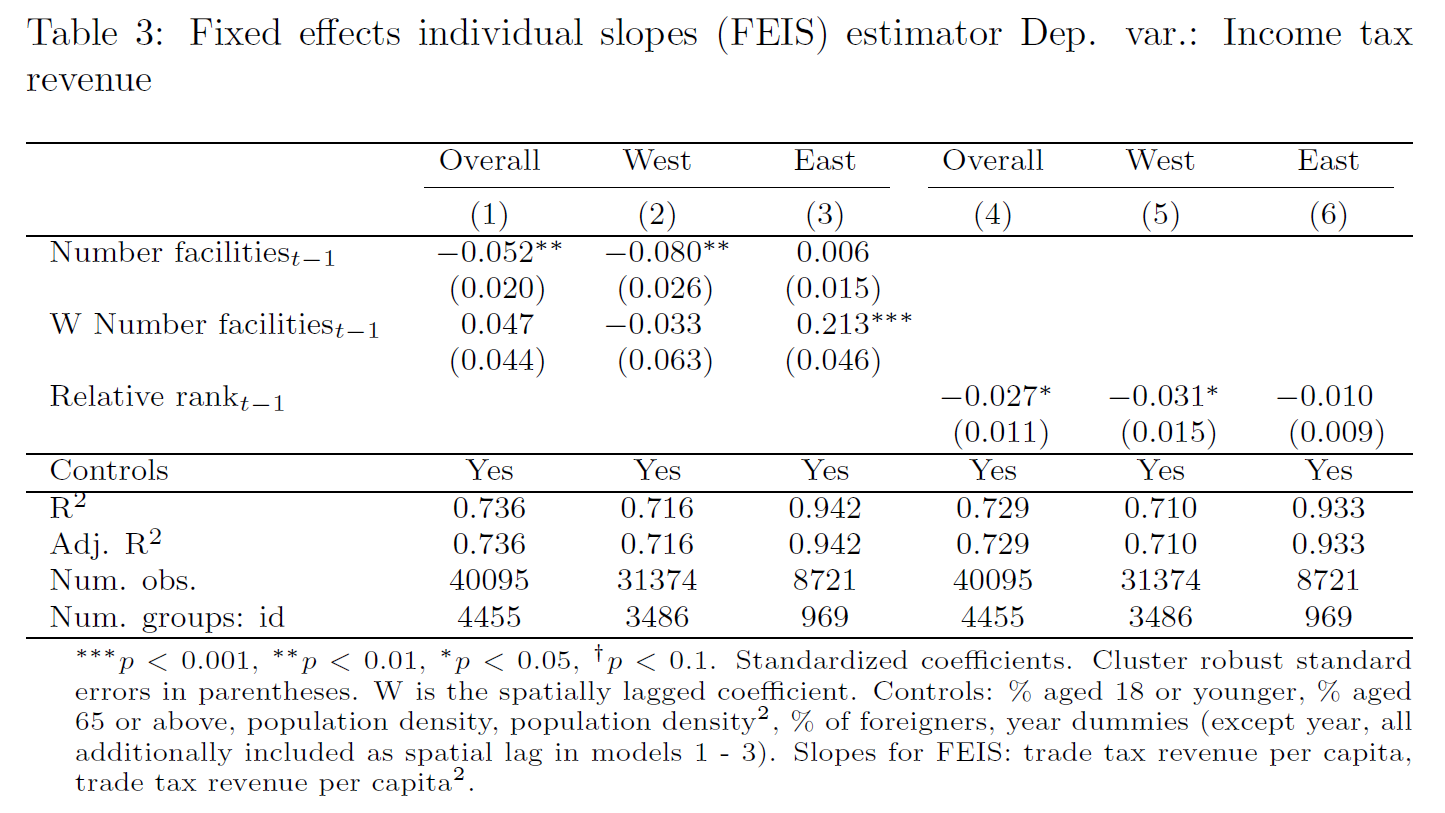
14.5 Example: Industrial facilities and municipal income
Rüttenauer and Best (2021): Environmental Inequality and Residential Sorting in Germany: A Spatial Time-Series Analysis of the Demographic Consequences of Industrial Sites. Demography, 58(6), 2243–2263. https://doi.org/10.1215/00703370-9563077