5 Detecting Spatial Dependence
\[ \newcommand{\tr}{\mathrm{tr}} \newcommand{\rank}{\mathrm{rank}} \newcommand{\plim}{\operatornamewithlimits{plim}} \newcommand{\diag}{\mathrm{diag}} \newcommand{\bm}[1]{\boldsymbol{\mathbf{#1}}} \newcommand{\Var}{\mathrm{Var}} \newcommand{\Exp}{\mathrm{E}} \newcommand{\Cov}{\mathrm{Cov}} \newcommand\given[1][]{\:#1\vert\:} \newcommand{\irow}[1]{% \begin{pmatrix}#1\end{pmatrix} } \]
Required packages
Session info
R version 4.6.0 (2026-04-24 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26200)
Matrix products: default
LAPACK version 3.12.1
locale:
[1] LC_COLLATE=German_Germany.utf8 LC_CTYPE=German_Germany.utf8
[3] LC_MONETARY=German_Germany.utf8 LC_NUMERIC=C
[5] LC_TIME=German_Germany.utf8
time zone: Europe/Berlin
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods
[7] base
other attached packages:
[1] viridisLite_0.4.3 tmap_4.4 spdep_1.4-2
[4] spData_2.3.5 mapview_2.11.4 gstat_2.1-6
[7] sf_1.1-1
loaded via a namespace (and not attached):
[1] xfun_0.57 raster_3.6-32 htmlwidgets_1.6.4
[4] lattice_0.22-9 tools_4.6.0 crosstalk_1.2.2
[7] parallel_4.6.0 stats4_4.6.0 proxy_0.4-29
[10] spacetime_1.3-3 xts_0.14.2 KernSmooth_2.23-26
[13] satellite_1.0.6 data.table_1.18.4 RColorBrewer_1.1-3
[16] leaflet_2.2.3 lifecycle_1.0.5 compiler_4.6.0
[19] farver_2.1.2 deldir_2.0-4 FNN_1.1.4.1
[22] microbenchmark_1.5.0 terra_1.9-27 codetools_0.2-20
[25] leafsync_0.1.0 leaflegend_1.2.8 stars_0.7-2
[28] htmltools_0.5.9 class_7.3-23 classInt_0.4-11
[31] lwgeom_0.2-16 wk_0.9.5 boot_1.3-32
[34] abind_1.4-8 digest_0.6.39 fastmap_1.2.0
[37] grid_4.6.0 colorspace_2.1-2 cli_3.6.6
[40] logger_0.4.2 magrittr_2.0.5 maptiles_0.11.0
[43] base64enc_0.1-6 XML_3.99-0.23 cols4all_0.10
[46] leafem_0.2.5 e1071_1.7-17 scales_1.4.0
[49] sp_2.2-1 rmarkdown_2.31 otel_0.2.0
[52] zoo_1.8-15 png_0.1-9 evaluate_1.0.5
[55] knitr_1.51 tmaptools_3.3 s2_1.1.11
[58] rlang_1.2.0 Rcpp_1.1.1-1.1 glue_1.8.1
[61] DBI_1.3.0 rstudioapi_0.18.0 jsonlite_2.0.0
[64] R6_2.6.1 spacesXYZ_1.6-0 intervals_0.15.5
[67] units_1.0-1 Reload data from pervious session
load("_data/msoa2_spatial.RData")5.1 Global Autocorrelation
If spatially close observations are more likely to exhibit similar values, we cannot handle observations as if they were independent.
\[ \Exp(\varepsilon_i\varepsilon_j)\neq \Exp(\varepsilon_i)\Exp(\varepsilon_j) = 0 \]
This violates a basic assumption of the conventional OLS model. We will talk more about whether that is good or bad (any guess?).
5.1.1 Visualization
There is one very easy and intuitive way of detecting spatial autocorrelation: Just look at the map. We do so by using tmap for plotting the share of home owners.
mp1 <- tm_shape(msoa.spdf) +
tm_polygons(
fill = "per_owner",
fill_alpha = 1,
fill.scale = tm_scale_intervals(
style = "fisher",
n = 8,
values = viridis(n = 8, direction = -1, option = "C")
),
fill.legend = tm_legend(
title = "Median",
hist = TRUE
),
fill.chart = tm_chart_histogram() # add a histogram to the legend
) +
tm_borders(col = "black", lwd = 1) +
tm_layout(
legend.frame = TRUE,
legend.bg.color = "white",
legend.outside = TRUE,
title.snap.to.legend = TRUE
) +
tm_title_out(
text = "Percent home owners",
position = tm_pos_out("center", "top", pos.h = "center"),
size = 1.6
)
mp1
We definitely see some clusters with spatial units having a low share of home owner (e.g. in the city center), and other clusters where home ownership is high (e.g. suburbs in the south and east, such as Bromley or Havering).
However, this is (to some degree) dependent on how we define cutoffs and coloring of the map: the Modifiable Areal Unit Problem (Wong 2009).
Which of the following three checkerboards has no (or the lowest) autocorrelation?

Would your answer be the same if we would aggregate the data to four larger areas / districts using the average within each of the four districts?
5.1.2 Moran’s I
The most common and well known statistic for spatial dependence or autocorrelation is Moran’s I, which goes back to Moran (1950) and Cliff and Ord (1972). For more extensive materials on Moran’s I see for instance Kelejian and Piras (2017), Chapter 11.
To calculate Moran’s I, we first define a neighbours weights matrix W.
Global Moran’s I test statistic: \[ \bm I = \frac{N}{S_0} \frac{\sum_i\sum_j w_{ij}(y_i-\bar{y})(y_j-\bar{y})} {\sum_i (y_i-\bar{y})^2}, \text{where } S_0 = \sum_{i=1}^N\sum_{j=1}^N w_{ij} \] It is often written with deviations \(z\)
\[ \bm I = \frac{N}{S_0} \frac{\sum_i\sum_j w_{ij}(z_i)(z_j)} {\sum_i (z_i)^2}, \text{where } S_0 = \sum_{i=1}^N\sum_{j=1}^N w_{ij} \]
Note that in the case of row-standardized weights, \(S_0 = N\). The \(I\) can be interpreted as: Relation of the deviation from the mean value between unit \(i\) and neighbours of unit \(i\). Basically, this measures correlation between neighbouring values.
Negative values: negative autocorrelation
Around zero: no autocorrelation
Positive values: positive autocorrelation
To calculate Moran’s I, we first need to define the relationship between units. As in the previous example, we define contiguity weights and distance-based weights.
# Contiguity (Queens) neighbours weights
queens.nb <- poly2nb(msoa.spdf,
queen = TRUE,
snap = 1) # we consider points in 1m distance as 'touching'
queens.lw <- nb2listw(queens.nb,
style = "W")
# Neighbours within 3km distance
coords <- st_geometry(st_centroid(msoa.spdf))Warning: st_centroid assumes attributes are constant over
geometriesdist_3.nb <- dnearneigh(coords,
d1 = 0, d2 = 3000)Warning in dnearneigh(coords, d1 = 0, d2 = 3000): neighbour object
has 2 sub-graphsidw.lw <- nb2listwdist(dist_3.nb,
x = coords, # needed for idw
type = "idw", # inverse distance weighting
alpha = 1, # the decay parameter for distance weighting
style = "minmax") # for eigenvalue normalizationSubsequently, we can calculate the average correlation between neighbouring units.
For contiguity weights, we get:
# Global Morans I test of housing values based on contiguity weights
moran.test(msoa.spdf$per_owner, listw = queens.lw, alternative = "two.sided")
Moran I test under randomisation
data: msoa.spdf$per_owner
weights: queens.lw
Moran I statistic standard deviate = 38.161, p-value <
2.2e-16
alternative hypothesis: two.sided
sample estimates:
Moran I statistic Expectation Variance
0.728706855 -0.001018330 0.000365663 And for inverse distance weighting, we get:
# Global Morans I test of housing values based on idw
moran.test(msoa.spdf$per_owner, listw = idw.lw, alternative = "two.sided")
Moran I test under randomisation
data: msoa.spdf$per_owner
weights: idw.lw
Moran I statistic standard deviate = 65.853, p-value <
2.2e-16
alternative hypothesis: two.sided
sample estimates:
Moran I statistic Expectation Variance
0.6838957350 -0.0010183299 0.0001081719 Interpretation: In both cases, we have very strong autocorrelation between neighbouring/closer units (~.7). It barely matters which of the weights matrices we use. This autocorrelation is highly significant. we can thus reject the Null that units are independent of each other (at least at this spatial level and for the share of home owners).
5.1.3 Residual-based Moran’s I
We can also use the same Moran’s I test to inspect spatial autocorrelation in residuals from an estimated linear model.
Let’s start with an intercept only model.
lm0 <- lm(per_owner ~ 1, msoa.spdf)
lm.morantest(lm0, listw = queens.lw, alternative = "two.sided")
Global Moran I for regression residuals
data:
model: lm(formula = per_owner ~ 1, data = msoa.spdf)
weights: queens.lw
Moran I statistic standard deviate = 38.177, p-value <
2.2e-16
alternative hypothesis: two.sided
sample estimates:
Observed Moran I Expectation Variance
0.7287068548 -0.0010183299 0.0003653613 This is exactly what we have received in the general case of Moran’s I.
Now, lets add some predictors. For instance, the distance to the city centre, and the population density may be strongly related to the home ownership rates and explain parts of the spatial dependence.
### Distance to city center
# Define centre
centre <- st_as_sf(data.frame(lon = -0.128120855701165,
lat = 51.50725909644806),
coords = c("lon", "lat"),
crs = 4326)
# Reproject
centre <- st_transform(centre, crs = st_crs(msoa.spdf))
# Calculate distance
msoa.spdf$dist_centre <- as.numeric(st_distance(msoa.spdf, centre)) / 1000
# hist(msoa.spdf$dist_centre)
### Run model with predictors
lm1 <- lm(per_owner ~ dist_centre + POPDEN, msoa.spdf)
lm.morantest(lm1, listw = queens.lw, alternative = "two.sided")
Global Moran I for regression residuals
data:
model: lm(formula = per_owner ~ dist_centre + POPDEN, data =
msoa.spdf)
weights: queens.lw
Moran I statistic standard deviate = 22.674, p-value <
2.2e-16
alternative hypothesis: two.sided
sample estimates:
Observed Moran I Expectation Variance
0.4298146060 -0.0024065617 0.0003633607 There is still considerable auto-correlation in the residuals. However, we have reduced it by a substantial amount with two very simple control variables.
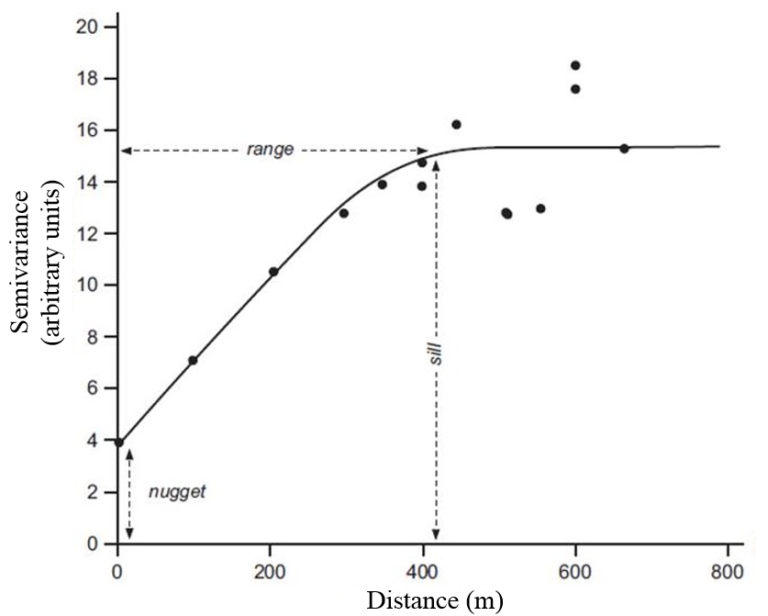
5.1.4 Semivariogram
The sample variogram \(\gamma(h)\) for distance intervals \(h_i\) describes the average square difference between the points in this distance interval:
\[ \hat{\gamma}(h_i) = \frac{1}{2N(h_i)}\sum_{j=1}^{N(h_i)}(z(s_i)-z(s_i+h'))^2, \ \ h_{i,0} \le h' < h_{i,1} \]
with the number of available pairs \(N(h_i)\) in each distance interval \(h_i\). Basically, it is the variance within each distance interval.
For more information, see for instance the Geospatial Data Science in R by Zia Ahmed or Pebesma and Bivand (2023).
To calculate the empirical semi-variogram, we can use the package gstat with the function variogram().
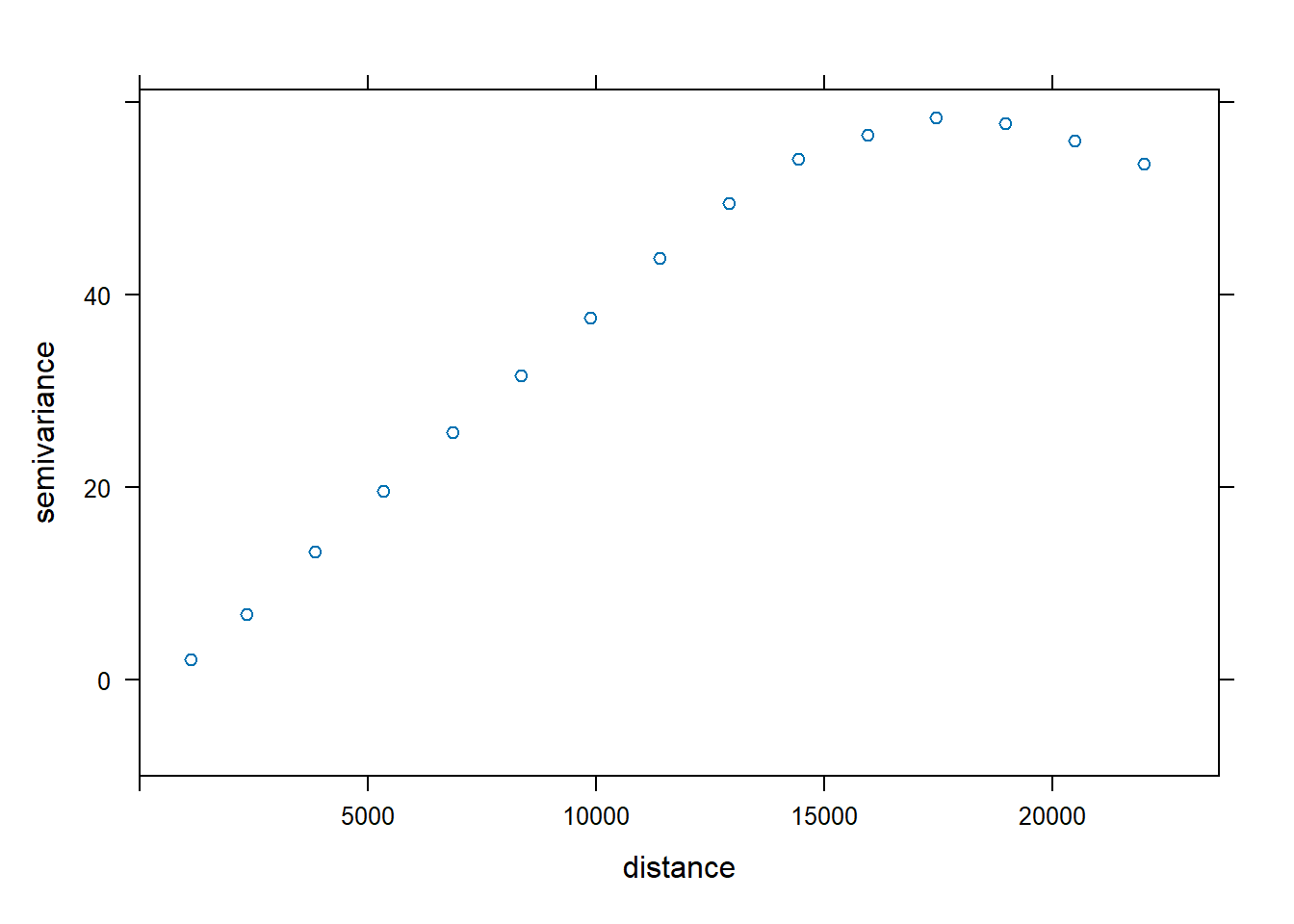
Above graphs shows that the variance within each distance interval gradually increases, up to a distance of ~ 18km, and then level off at a relative constant level. Lower variances within lower values of distances means that observations are more similar to each other the closer they are.
We can also try to fit a model that resembles the spatial structure. This becomes important when we want to perform spatial interpolation (e.g. to impute missings).
# Intial parameter set by eye esitmation
m.no2 <- vgm(60, "Cir", 20000, 0) # Sill, model, range, nugget
# least square fit
m.f.v.no2 <- gstat::fit.variogram(v.no2, m.no2)#### Plot varigram and fitted model:
plot(v.no2, pl = FALSE,
model = m.f.v.no2,
col="blue",
cex = 0.9,
lwd = 0.5,
lty = 1,
pch = 19,
main = "Variogram and Fitted Model",
xlab = "Distance (m)",
ylab = "Semivariance")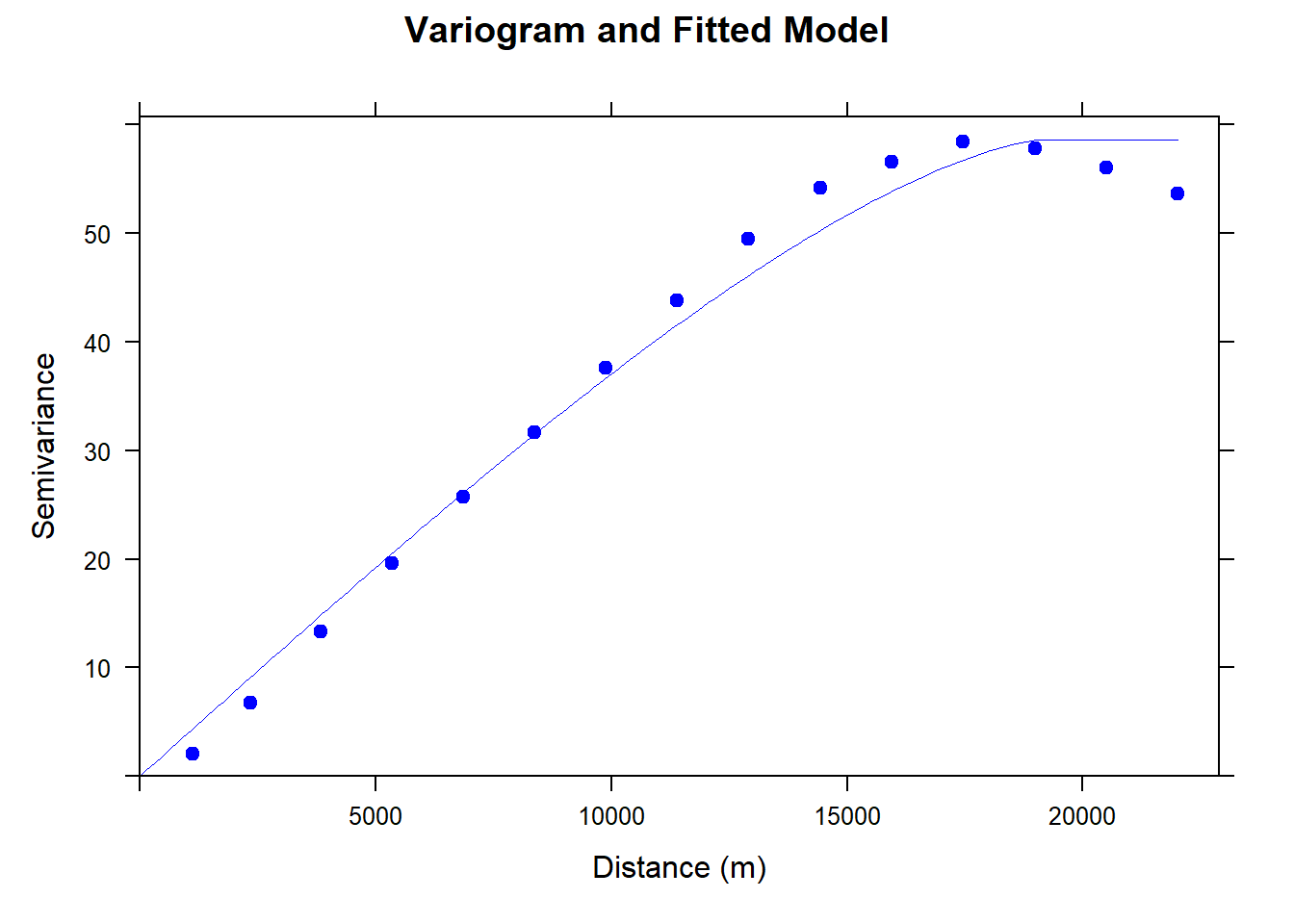
5.1.5 Example
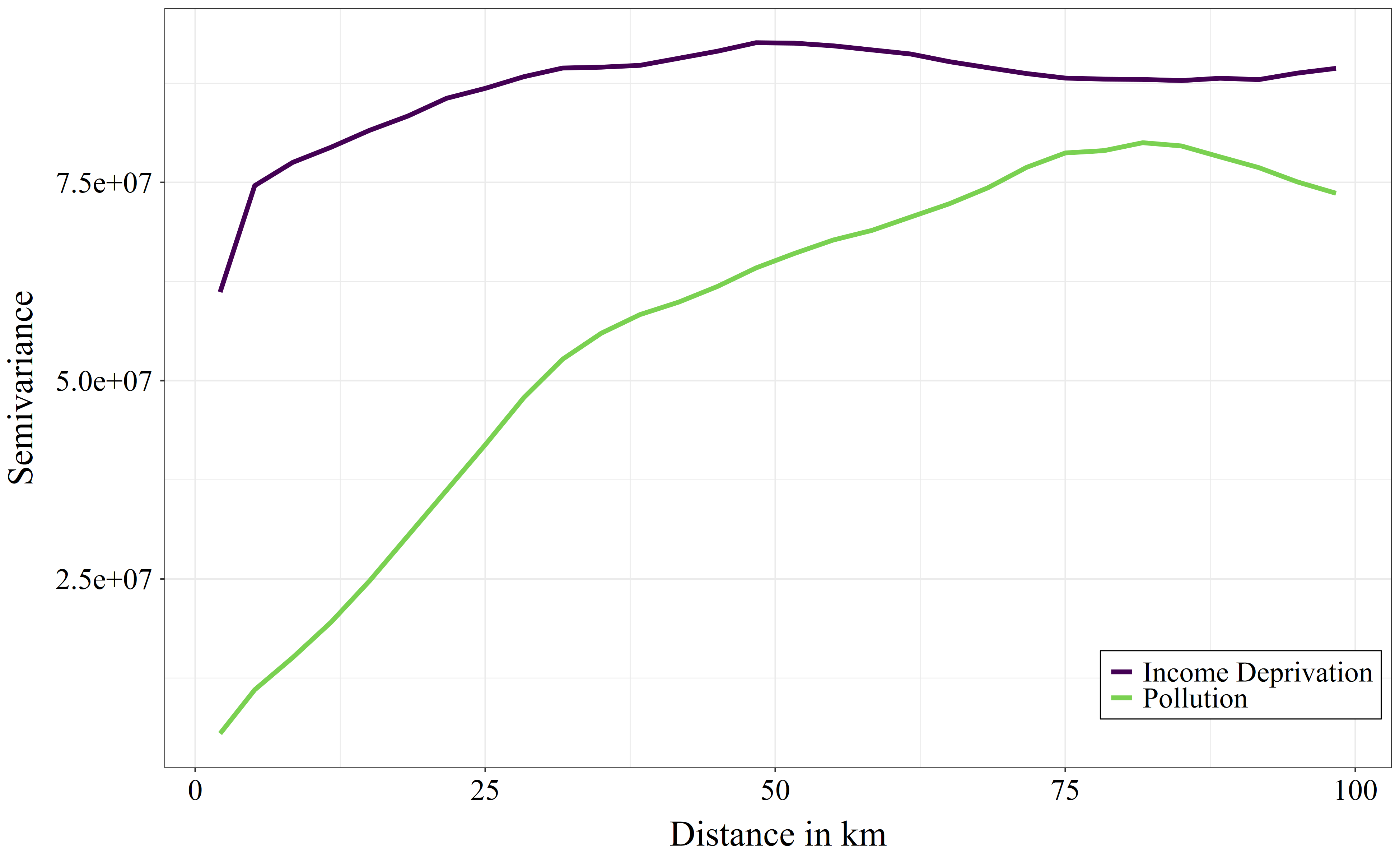
When looking at approx. 10 km distance: the variance in income deprivation is nearly as high when looking at areas within 10km as it would be when looking at areas within 100km distance. This indicates that income deprivation is very local and varies already within smaller areas such as within cities or district. Air pollution, in contrast, has a much lower variance within 10km distances than we would find when looking at the data within 100km distance. This indicates that air pollution has stronger large-scale spatial patterns. When moving locally (e.g. within 10km) to a random location, it would be more difficult to improve in air pollution than it would be to improve in income deprivation.
5.2 Local Autocorrelation
The Global Moran’s I statistic above summarizes the spatial pattern by a single value. Although this is helpful to get a feeling of the strength of the general spatial association, it is often more helpful to inspect the spatial pattern in more detail.
The most prominent measure is the Local Indicators of Spatial Association (LISA) (Anselin 1995). LISA measures assess the importance and significance of a satistic at different spatial locations. For more information see for instance the GeoData Materials by Luc Anselin.
For instance, we can use the Moran Plot to identify how single (pairs of) units contribute to the overall dependence.
mp <- moran.plot(msoa.spdf$per_owner, queens.lw)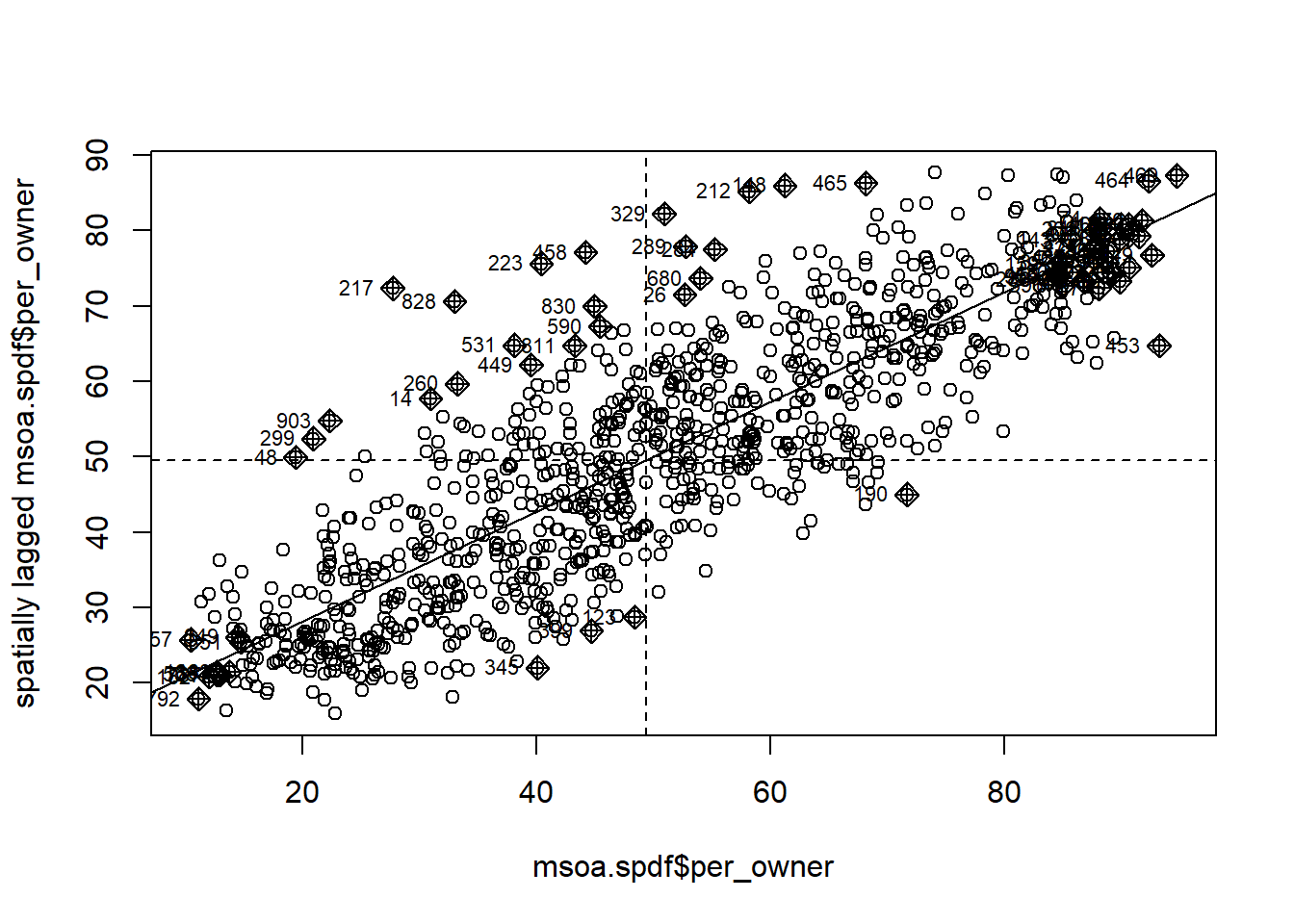
In the lower left corner, we see units with a low-low share of home ownership: focal and neighbouring units have a low share of home owners. In the top right corner, by contrast, we see high-high units.
And we can plot influence values on the Overall Moran statistic.
msoa.spdf$hat_value <- mp$hat
mp1 <- tm_shape(msoa.spdf) +
tm_polygons(
fill = "hat_value",
fill_alpha = 1,
fill.scale = tm_scale_intervals(
values = viridis(n = 10, direction = -1, option = "C")
)
) +
tm_borders(col = "white", lwd = 0.5, fill_alpha = 0.5) +
tm_layout(
frame = FALSE,
legend.frame = TRUE,
legend.bg.color = "white",
legend.position = c("right", "bottom"),
legend.outside = FALSE,
legend.title.size = 0.8,
legend.text.size = 0.8
) +
tm_title_out(
text = "Influence",
position = tm_pos_out("center", "top", pos.h = "center"),
size = 1.6
)
mp1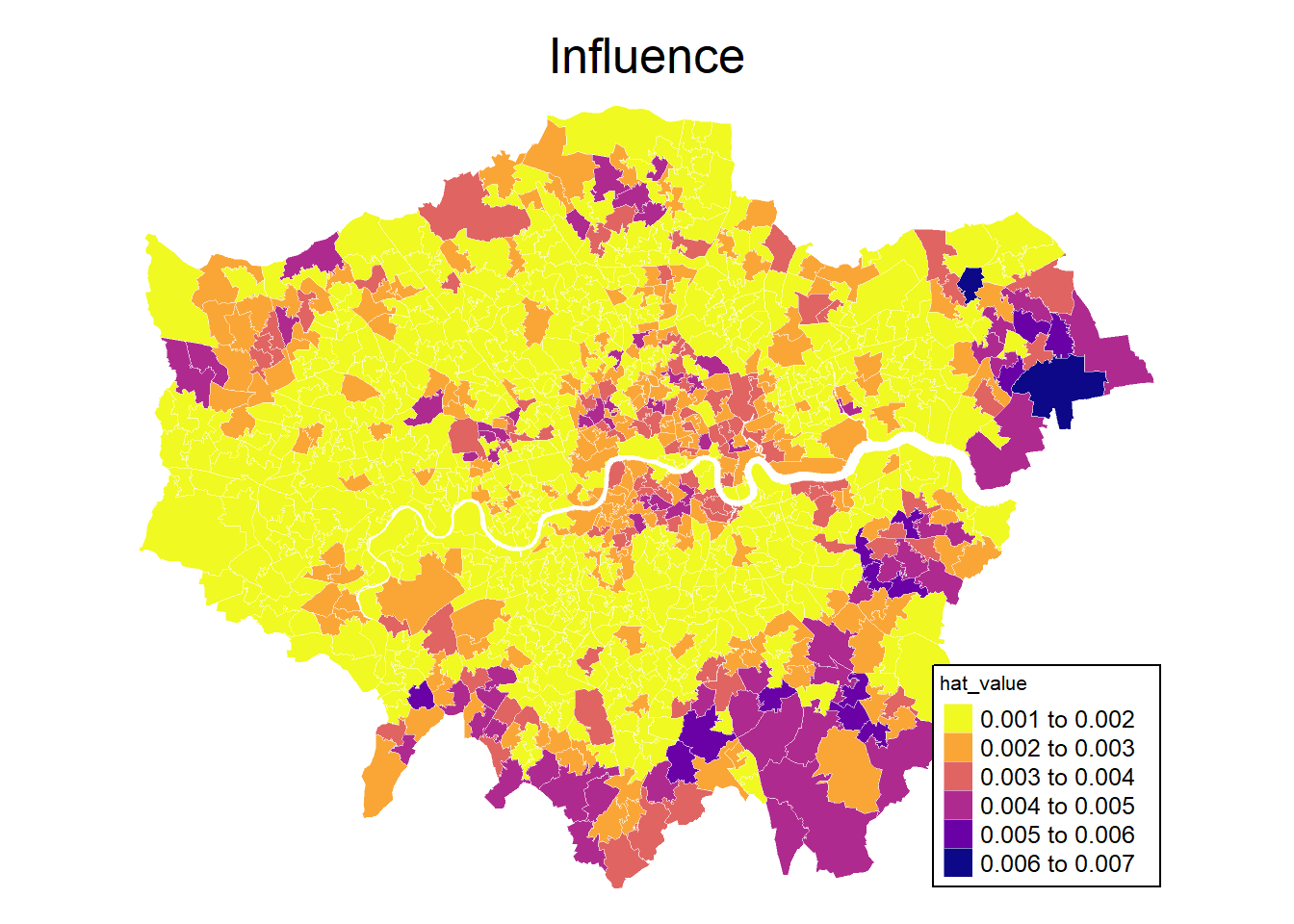
5.3 Local Moran’s I
Local Moran’s I is a local version of the overall Moran’s I to identify local clusters and local spatial outliers (Anselin 1995). The Local Moran’s I is just a local version which is calculated for each location:
\[
\bm I_i =
\frac{z_i \sum_j w_{ij}z_j}
{\sum_i (z_i)^2 / (n-1)}, \text{where }
\] We use the function localmoran() to calculate the local test statistic .
loci <- localmoran(msoa.spdf$per_owner, listw = queens.lw)
head(loci) Ii E.Ii Var.Ii Z.Ii Pr(z != E(Ii))
1 0.42322928 -1.285364e-04 0.011367934 3.9706976 7.166249e-05
2 -0.12775982 -2.229957e-05 0.003634711 -2.1187688 3.411001e-02
3 0.38111534 -6.569549e-04 0.091630752 1.2611995 2.072370e-01
4 1.02874685 -1.428679e-03 0.279333375 1.9491704 5.127507e-02
5 0.08553291 -2.108521e-04 0.041275789 0.4220412 6.729949e-01
6 -0.24014505 -2.228818e-04 0.036321252 -1.2588964 2.080678e-01It also has an attribute with the Moran plot quadrant of each observation.
mean median pysal
1 Low-Low Low-Low Low-Low
2 Low-High Low-High Low-High
3 High-High High-High High-High
4 High-High High-High High-High
5 High-High High-High High-High
6 Low-High Low-High Low-HighThis returns a data.frame with local moran statisic, the expectation of local moran statistic, its variance, and a p value for the satistical significance of each unit. Note that we obviously have a problem of multiple comparisons here and thus may want to correct the significance level, e.g. by Bonferroni adjustment (Bivand and Wong 2018).
mp1 <- tm_shape(msoa.spdf) +
tm_polygons(
fill = c("loci", "p_value", "p_value_adj1", "p_value_adj2"),
fill_alpha = 1,
fill.scale = tm_scale_intervals(
values = viridis(n = 10, direction = -1, option = "C")
)
) +
tm_borders(col = "white", lwd = 0.5, fill_alpha = 0.5) +
tm_layout(
frame = FALSE,
legend.frame = TRUE,
legend.bg.color = "white",
legend.position = c("left", "bottom"),
legend.outside = FALSE,
legend.title.size = 0.8,
legend.text.size = 0.8,
panel.labels = c("Morans I", "P value", "p value BY", "p value Bonferroni")
) +
tm_title_out(
text = "Local Morans I",
position = tm_pos_out("center", "top", pos.h = "center"),
size = 1.6
)
mp1[plot mode] fit legend/component: Some legend items or map
compoments do not fit well, and are therefore rescaled.
ℹ Set the tmap option `component.autoscale = FALSE` to disable
rescaling.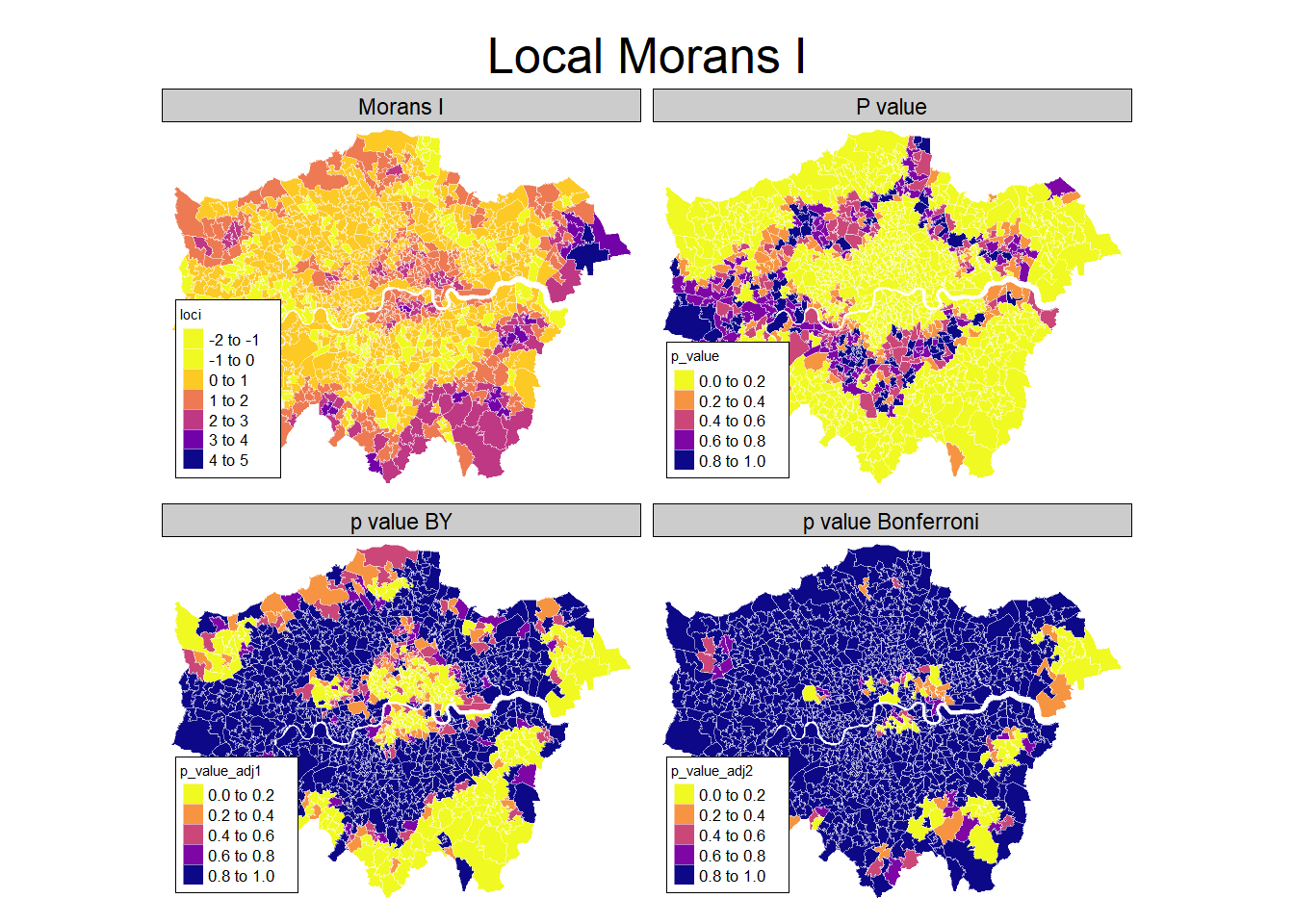
Something you can often see are so called LISA hotspot maps. They are based on the same idea as the moran plot, and show cluster of high-high and low-low values. We can use the hotspot function to identify the clusters, with a cutoff for singificance and the adjustment for multiple testing.
# Calculate clusters
msoa.spdf$lisa_cluster <- hotspot(loci,
"Pr(z != E(Ii))",
cutoff = 0.05,
quadrant.type = "mean",
p.adjust = "BY")
# Map
mp1 <- tm_shape(msoa.spdf) +
tm_polygons(
fill = "lisa_cluster",
fill_alpha = 1,
fill.scale = tm_scale_categorical(
values = viridis(n = 3, direction = -1, option = "D"),
value.na = "grey92"
),
fill.legend = tm_legend(
na.show = FALSE,
title = "Clusters"
)
) +
tm_borders(col = "grey70", lwd = 0.5, fill_alpha = 0.5) +
tm_layout(
frame = FALSE,
legend.frame = TRUE,
legend.bg.color = "white",
legend.position = c("left", "bottom"),
legend.outside = FALSE,
legend.title.size = 0.8,
legend.text.size = 0.8
) +
tm_title_out(
text = "Home Ownership \n LISA Clusters p(BY) < 0.05",
position = tm_pos_out("center", "top", pos.h = "center"),
size = 1.6
)
mp1
Note that it is not suggested to interpret those cluster as singificant in the strict statistical sense. Pebesma and Bivand (2023) suggest to speak of interesting clusters. After all, this is an explorative approach. Nevertheless, it can help to identify spatial patterns and clusters.
There are more ways of calculating these hotspot maps and more choices on the cutoffs and calculation of the statistical significance. For more materials see Chapter 15 of Pebesma and Bivand (2023).
5.4 Example
Koks et al. (2015)
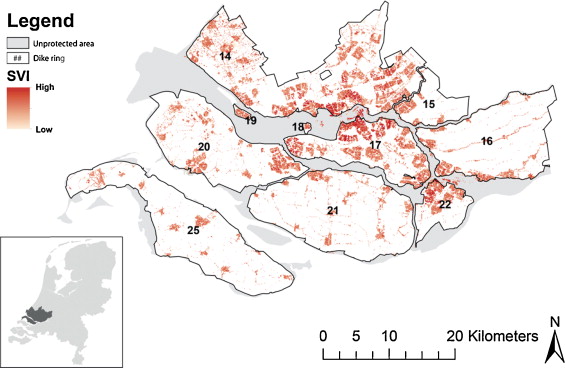
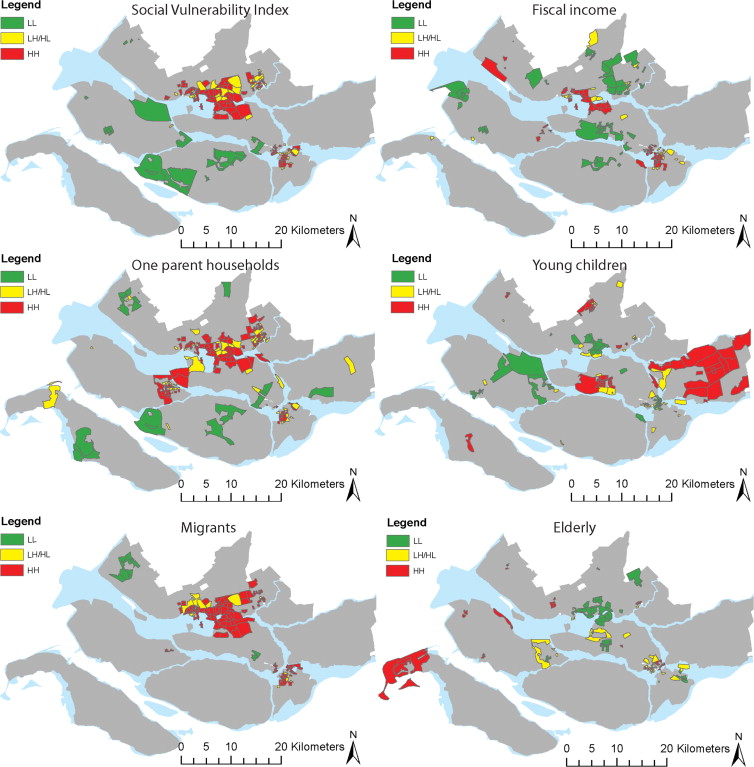
The upper left map in Fig. 5 shows that several neighborhoods with a high SVI are surrounded by areas consisting of a population with a high SVI as well, with a few exceptions of a low SVI ‘neighborhood’ being located in between high SVI groups. … Comparing the upper left map (the aggregate SVI) with the other maps (the underlying factors), we see that that fiscal income, one-parent households and migrants have similar clustering patterns as the SVI. These clusters can again mainly be found in the cities of Rotterdam and Dordrecht.
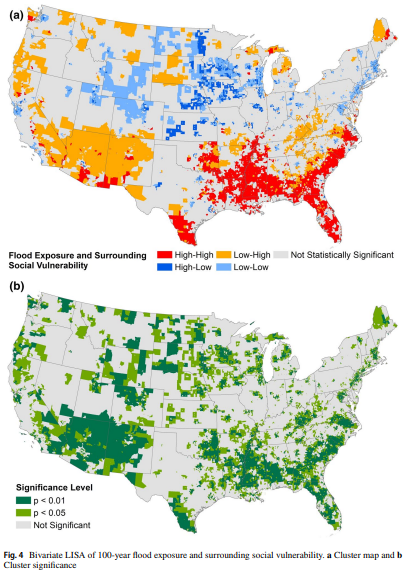
Tate et al. (2021)
This study explores the geography of flood exposure and social vulnerability in the conterminous United States based on spatial analysis of fluvial and pluvial flood extent, land cover, and social vulnerability.
Mobile homes and racial minorities are most overrepresented in hotspots compared to elsewhere. The results identify priority locations where interventions can mitigate both physical and social aspects of flood vulnerability.