13 Exercises IIIb
\[ \newcommand{\tr}{\mathrm{tr}} \newcommand{\rank}{\mathrm{rank}} \newcommand{\plim}{\operatornamewithlimits{plim}} \newcommand{\diag}{\mathrm{diag}} \newcommand{\bm}[1]{\boldsymbol{\mathbf{#1}}} \newcommand{\Var}{\mathrm{Var}} \newcommand{\Exp}{\mathrm{E}} \newcommand{\Cov}{\mathrm{Cov}} \newcommand\given[1][]{\:#1\vert\:} \newcommand{\irow}[1]{% \begin{pmatrix}#1\end{pmatrix} } \]
Required packages
Session info
R version 4.6.0 (2026-04-24 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26200)
Matrix products: default
LAPACK version 3.12.1
locale:
[1] LC_COLLATE=German_Germany.utf8 LC_CTYPE=German_Germany.utf8
[3] LC_MONETARY=German_Germany.utf8 LC_NUMERIC=C
[5] LC_TIME=German_Germany.utf8
time zone: Europe/Berlin
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods
[7] base
other attached packages:
[1] SDPDmod_0.0.7 splm_1.6-5 lfe_3.1.1
[4] plm_2.6-7 viridis_0.6.5 viridisLite_0.4.3
[7] tmap_4.4 ggplot2_4.0.3 spatialreg_1.4-3
[10] Matrix_1.7-5 spdep_1.4-2 spData_2.3.5
[13] mapview_2.11.4 sf_1.1-1
loaded via a namespace (and not attached):
[1] Rdpack_2.6.6 DBI_1.3.0
[3] deldir_2.0-4 gridExtra_2.3
[5] tmaptools_3.3 s2_1.1.11
[7] logger_0.4.2 sandwich_3.1-1
[9] rlang_1.2.0 magrittr_2.0.5
[11] dreamerr_1.5.0 multcomp_1.4-30
[13] otel_0.2.0 e1071_1.7-17
[15] compiler_4.6.0 png_0.1-9
[17] vctrs_0.7.3 stringr_1.6.0
[19] pkgconfig_2.0.3 wk_0.9.5
[21] fastmap_1.2.0 backports_1.5.1
[23] lwgeom_0.2-16 leafem_0.2.5
[25] rmarkdown_2.31 spacesXYZ_1.6-0
[27] miscTools_0.6-30 xfun_0.57
[29] satellite_1.0.6 jsonlite_2.0.0
[31] stringmagic_1.2.0 collapse_2.1.7
[33] terra_1.9-27 parallel_4.6.0
[35] LearnBayes_2.15.2 R6_2.6.1
[37] stringi_1.8.7 RColorBrewer_1.1-3
[39] boot_1.3-32 numDeriv_2016.8-1.1
[41] lmtest_0.9-40 stars_0.7-2
[43] Rcpp_1.1.1-1.1 knitr_1.51
[45] zoo_1.8-15 base64enc_0.1-6
[47] splines_4.6.0 tidyselect_1.2.1
[49] rstudioapi_0.18.0 abind_1.4-8
[51] maptiles_0.11.0 maxLik_1.5-2.2
[53] codetools_0.2-20 lattice_0.22-9
[55] tibble_3.3.1 leafsync_0.1.0
[57] withr_3.0.2 S7_0.2.2
[59] coda_0.19-4.1 evaluate_1.0.5
[61] marginaleffects_0.32.0 survival_3.8-6
[63] fixest_0.14.1 units_1.0-1
[65] proxy_0.4-29 pillar_1.11.1
[67] KernSmooth_2.23-26 stats4_4.6.0
[69] generics_0.1.4 sp_2.2-1
[71] scales_1.4.0 xtable_1.8-8
[73] class_7.3-23 glue_1.8.1
[75] tools_4.6.0 leaflegend_1.2.8
[77] data.table_1.18.4 RSpectra_0.16-2
[79] dotCall64_1.2 mvtnorm_1.3-7
[81] XML_3.99-0.23 grid_4.6.0
[83] rbibutils_2.4.1 crosstalk_1.2.2
[85] bdsmatrix_1.3-7 colorspace_2.1-2
[87] nlme_3.1-169 cols4all_0.10
[89] raster_3.6-32 Formula_1.2-5
[91] cli_3.6.6 spam_2.11-4
[93] dplyr_1.2.1 gtable_0.3.6
[95] digest_0.6.39 classInt_0.4-11
[97] TH.data_1.1-5 htmlwidgets_1.6.4
[99] farver_2.1.2 htmltools_0.5.9
[101] lifecycle_1.0.5 leaflet_2.2.3
[103] microbenchmark_1.5.0 MASS_7.3-65 13.1 Inkar data: the effect of regional characteristics on life expectancy
Below, we read and transform some characteristics of the INKAR data on the level of German counties.
load("_data/inkar2.Rdata")Variables are
| Variable | Description |
|---|---|
| “Kennziffer” | ID |
| “Raumeinheit” | Name |
| “Aggregat” | Level |
| “year” | Year |
| “poluation_density” | Population Density |
| “median_income” | Median Household income (only for 2020) |
| “gdp_in1000EUR” | Gross Domestic Product in 1000 euros |
| “unemployment_rate” | Unemployment rate |
| “share_longterm_unemployed” | Share of longterm unemployed (among unemployed) |
| “share_working_indutry” | Share of employees in undistrial sector |
| “share_foreigners” | Share of foreign nationals |
| “share_college” | Share of school-finishers with college degree |
| “recreational_space” | Recreational space per inhabitant |
| “car_density” | Density of cars |
| “life_expectancy” | Life expectancy |
13.2 County shapes
kreise.spdf <- st_read(dsn = "_data/vg5000_ebenen_1231",
layer = "VG5000_KRS")Reading layer `VG5000_KRS' from data source
`C:\work\Lehre\Geodata_Spatial_Regression\_data\vg5000_ebenen_1231'
using driver `ESRI Shapefile'
Simple feature collection with 400 features and 24 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 280353.1 ymin: 5235878 xmax: 921261.6 ymax: 6101302
Projected CRS: ETRS89 / UTM zone 32N1) Please map the life expectancy across Germany
- Merge data with the shape file (as with conventional data)
# Merge
inkar_2020.spdf <- merge(kreise.spdf, inkar.df[inkar.df$year == 2020, ],
by.x = "AGS", by.y = "Kennziffer")- Create a map of life-expectancy
cols <- viridis(n = 100, direction = -1, option = "G")
mp1 <- ggplot(data = inkar_2020.spdf) +
geom_sf(aes(fill = life_expectancy), color = "white", size = 0.5) +
scale_fill_gradientn(
colours = cols, # your custom palette
name = "in years",
na.value = "grey90"
) +
labs(title = "Life expectancy") +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 16),
legend.title = element_text(size = 10),
legend.text = element_text(size = 8),
legend.background = element_rect(fill = "white", color = "black"),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank()
)
mp1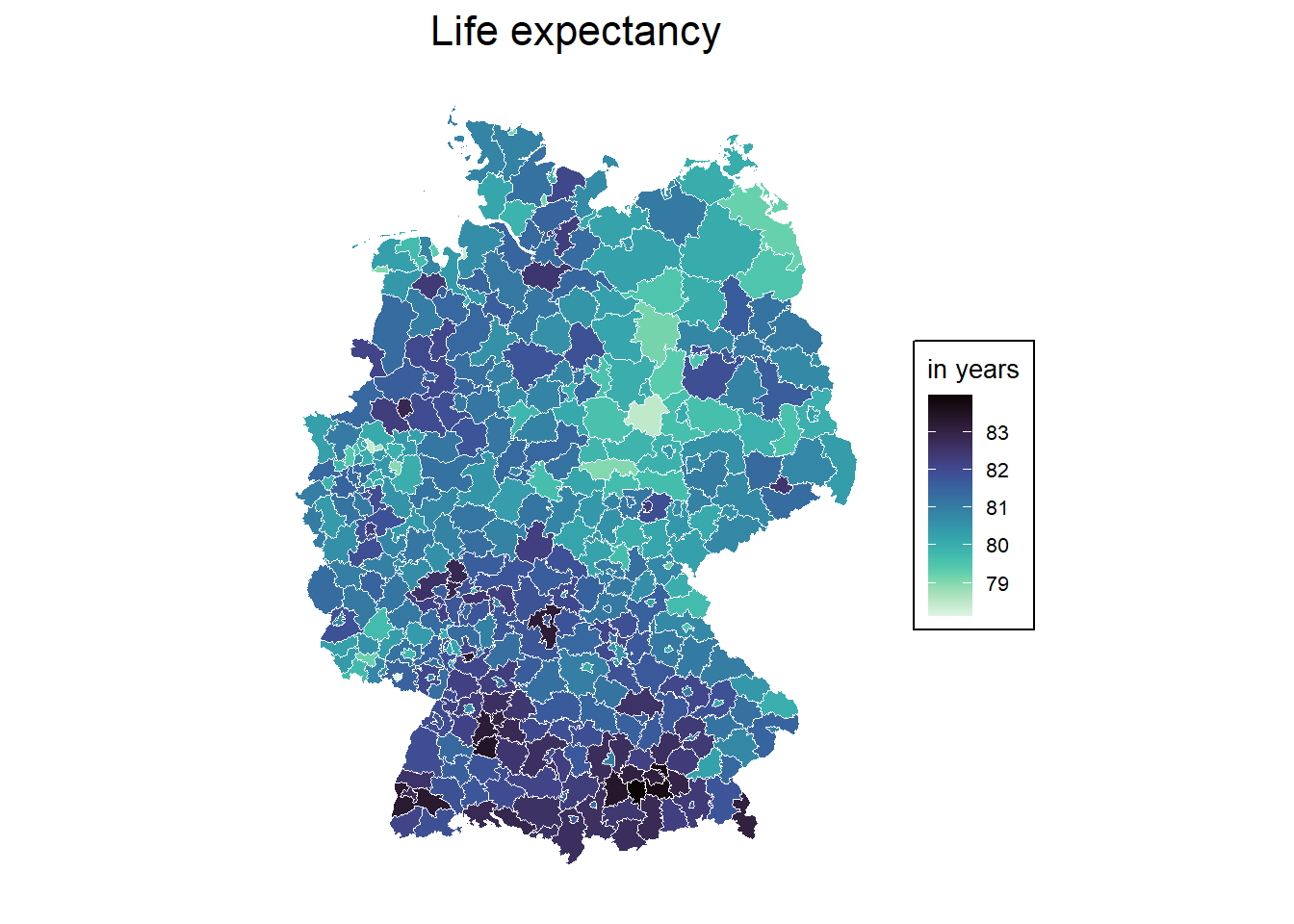
2) We want to know what the predicts the variation in life expectancy. Chose some variables that could predict life expectancy. See for instance the following paper.
3) Obviously, as good geospatial scholars, we might assume that it is not only the focal characteristics that matter, but maybe also the characteristics of surrounding counties. Please create a neighbours object such as the 10 nearest neighbours.
# nb <- poly2nb(kreise.spdf, row.names = "ags", queen = TRUE)
knn <- knearneigh(st_centroid(kreise.spdf), k = 10)Warning: st_centroid assumes attributes are constant over
geometriesnb <- knn2nb(knn, row.names = kreise.spdf$ags)
listw <- nb2listw(nb, style = "W")4) Please estimate a cross-sectional spatial model for the year 2020 that predicts life expectancy (as the depend variable) with the covariates that you have choosen above. Afterwards, please calculate the summary impacts using impacts().
### Use a spatial Durbin Error model
# Spec formula
fm <- life_expectancy ~ median_income + unemployment_rate + share_college + car_density
# Estimate error model with Durbin = TRUE
mod_1.durb <- errorsarlm(fm,
data = inkar_2020.spdf,
listw = listw,
Durbin = TRUE)
summary(mod_1.durb)
Call:
errorsarlm(formula = fm, data = inkar_2020.spdf, listw = listw,
Durbin = TRUE)
Residuals:
Min 1Q Median 3Q Max
-1.343984 -0.349567 0.013307 0.333106 1.819014
Type: error
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 8.4970e+01 1.4366e+00 59.1456 < 2.2e-16
median_income 5.4013e-04 8.2285e-05 6.5641 5.233e-11
unemployment_rate -3.8970e-01 2.0095e-02 -19.3923 < 2.2e-16
share_college 6.7806e-03 3.2502e-03 2.0862 0.036956
car_density -3.2042e-03 4.9774e-04 -6.4376 1.214e-10
lag.median_income 4.9282e-04 1.8112e-04 2.7209 0.006511
lag.unemployment_rate -3.4685e-02 4.5454e-02 -0.7631 0.445418
lag.share_college -1.7065e-03 7.0324e-03 -0.2427 0.808270
lag.car_density -5.2210e-03 1.7541e-03 -2.9765 0.002915
Lambda: 0.57895, LR test value: 48.146, p-value: 3.9563e-12
Asymptotic standard error: 0.069523
z-value: 8.3275, p-value: < 2.22e-16
Wald statistic: 69.347, p-value: < 2.22e-16
Log likelihood: -305.6855 for error model
ML residual variance (sigma squared): 0.26001, (sigma: 0.50991)
Number of observations: 400
Number of parameters estimated: 11
AIC: 633.37, (AIC for lm: 679.52)# Calculate impacts (which is unnecessary in this case)
mod_1.durb.imp <- impacts(mod_1.durb, listw = listw, R = 300)
summary(mod_1.durb.imp, zstats = TRUE, short = TRUE)Impact measures (SDEM, glht, n):
Direct Indirect Total
median_income dy/dx 0.0005401284 0.0004928188 0.001032947
unemployment_rate dy/dx -0.3896967422 -0.0346850810 -0.424381823
share_college dy/dx 0.0067806262 -0.0017064694 0.005074157
car_density dy/dx -0.0032042374 -0.0052209850 -0.008425222
========================================================
Standard errors:
Direct Indirect Total
median_income dy/dx 0.0000822846 0.0001811243 0.0001813217
unemployment_rate dy/dx 0.0200953892 0.0454542641 0.0455757529
share_college dy/dx 0.0032501555 0.0070323979 0.0069550103
car_density dy/dx 0.0004977411 0.0017540570 0.0018942566
========================================================
Z-values:
Direct Indirect Total
median_income dy/dx 6.564150 2.7208866 5.6967654
unemployment_rate dy/dx -19.392346 -0.7630765 -9.3115702
share_college dy/dx 2.086247 -0.2426583 0.7295686
car_density dy/dx -6.437558 -2.9765197 -4.4477726
p-values:
Direct Indirect Total
median_income dy/dx 5.2331e-11 0.0065107 1.2210e-08
unemployment_rate dy/dx < 2.22e-16 0.4454178 < 2.22e-16
share_college dy/dx 0.036956 0.8082701 0.46565
car_density dy/dx 1.2141e-10 0.0029154 8.6765e-065) Calculate the spatial lagged variables for the independent variables that you have included in the earlier model. You can use create_WX(), but note that it needs a non-spatial df as input for the original variables.
6) Bonus task: Can you run a spatial machine learning model?
For instance, you could use a random forest algorithm (e.g. randomForest()) and include the original variables but also the spatial lags of these variables. You could even go further and use higher order neighbours (e.g. nblag(queens.nb, maxlag = 3)) to check the importance of direct neighbours and the neighbours neighbours and so on …
randomForest 4.7-1.2Type rfNews() to see new features/changes/bug fixes.
Attache Paket: 'randomForest'Das folgende Objekt ist maskiert 'package:ggplot2':
margin# Train
rf.mod <- randomForest(life_expectancy ~ median_income + unemployment_rate + share_college + car_density +
w.median_income + w.unemployment_rate + w.share_college + w.car_density,
data = st_drop_geometry(inkar_2020.spdf),
ntree = 1000,
importance = TRUE)
# Inspect the mechanics of the model
importance(rf.mod) %IncMSE IncNodePurity
median_income 34.26700 42.60719
unemployment_rate 67.32795 115.26633
share_college 23.94434 26.40045
car_density 23.81031 33.34788
w.median_income 36.03729 58.14685
w.unemployment_rate 29.01545 52.88627
w.share_college 18.39497 24.43687
w.car_density 23.01376 29.58204varImpPlot(rf.mod)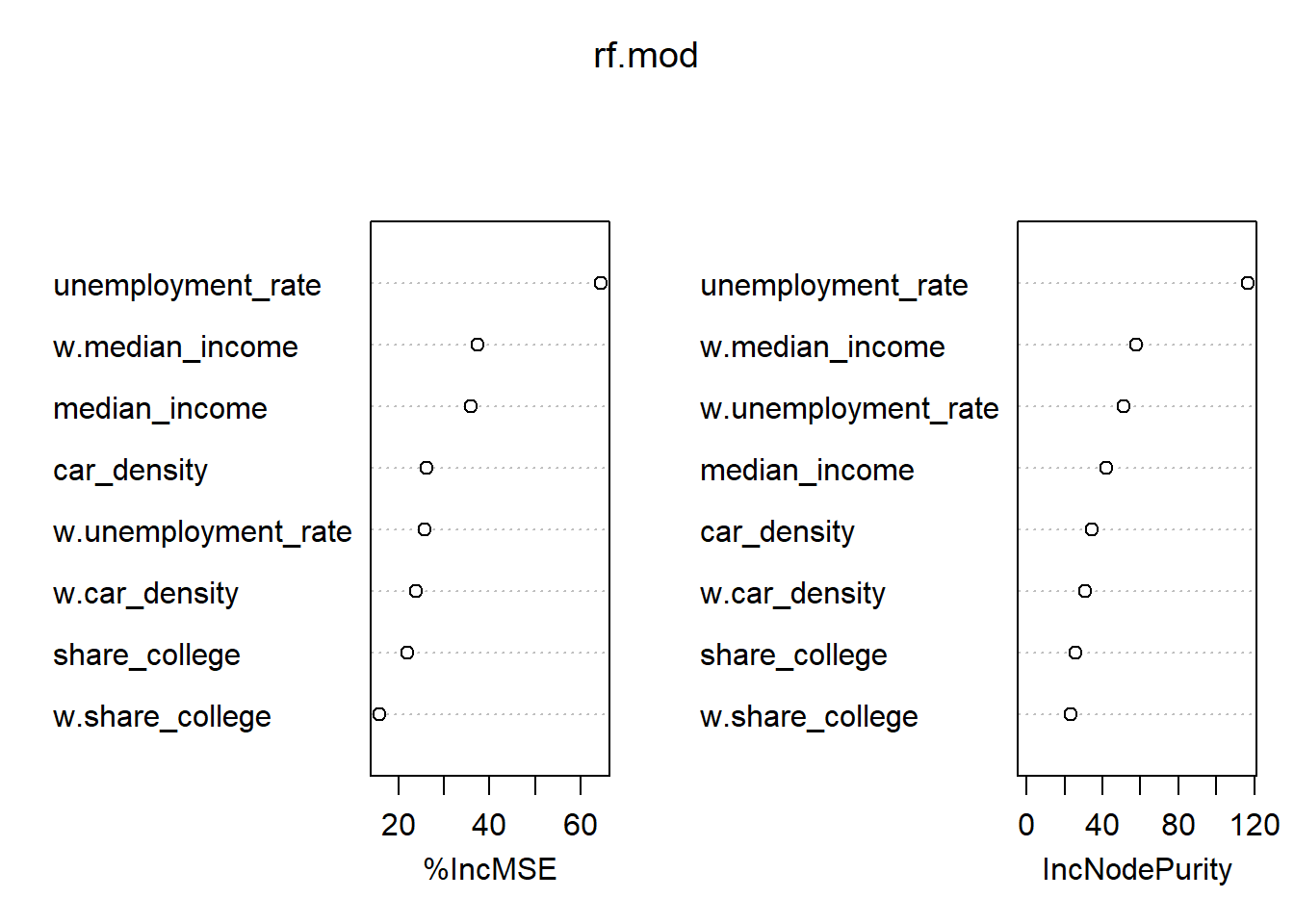
13.3 Bonus task: Estimate an FE model with SLX specification
- Loops over years to generate WX
# We use gdp instead of median income (which is only available in recent year)
fm <- life_expectancy ~ gdp_in1000EUR + unemployment_rate + share_college + car_density
# All years where we have a balanced sample
years <- unique(inkar.df$year[which(complete.cases(inkar.df[, all.vars(fm)]))])
# All variables we want ot lag
vars <- all.vars(fm)
# create listw with the correct rownames (ID = Kennziffer)
kreise.spdf$Kennziffer <- kreise.spdf$ags
knn <- knearneigh(st_centroid(kreise.spdf), k = 10)
nb <- knn2nb(knn, row.names = kreise.spdf$Kennziffer)
listw <- nb2listw(nb, style = "W")
for(y in years){
# Select singe year
tmp <- inkar.df[inkar.df$year == y ,]
# Select variables and make df
x <- st_drop_geometry(tmp[, vars])
# Add ID as rownames (we retreive them again later)
rownames(x) <- tmp$Kennziffer
# Perform lag transformation (rownames contian ids)
w.tmp <- create_WX(as.matrix(x),
listw = listw,
prefix = "w",
zero.policy = TRUE) # NAs will get zero
w.tmp <- as.data.frame(w.tmp)
# add indices back
w.tmp$Kennziffer <- row.names(w.tmp)
w.tmp$year <- y
if(y == years[1]){
w.inkar.df <- w.tmp
}else{
w.inkar.df <- rbind(w.inkar.df, w.tmp)
}
}
head(w.inkar.df) w.life_expectancy w.gdp_in1000EUR w.unemployment_rate
01001 77.386 3866035 10.257
01002 77.355 3812976 10.394
01003 77.237 10728945 11.666
01004 77.458 4586244 9.999
01051 77.291 4270208 10.007
01053 77.119 11012351 11.878
w.share_college w.car_density Kennziffer year
01001 18.558 518.092 01001 1998
01002 20.389 516.400 01002 1998
01003 23.075 497.344 01003 1998
01004 20.798 516.580 01004 1998
01051 18.957 520.985 01051 1998
01053 23.625 501.522 01053 1998- Estimate a twoways FE SLX panel model
slx.fe <- felm(life_expectancy ~ gdp_in1000EUR + unemployment_rate + share_college + car_density +
w.gdp_in1000EUR + w.unemployment_rate + w.share_college + w.car_density
| Kennziffer + year | 0 | Kennziffer,
data = inkar.df)
summary(slx.fe)
Call:
felm(formula = life_expectancy ~ gdp_in1000EUR + unemployment_rate + share_college + car_density + w.gdp_in1000EUR + w.unemployment_rate + w.share_college + w.car_density | Kennziffer + year | 0 | Kennziffer, data = inkar.df)
Residuals:
Min 1Q Median 3Q Max
-1.62945 -0.17351 0.00156 0.17930 1.58230
Coefficients:
Estimate Cluster s.e. t value Pr(>|t|)
gdp_in1000EUR 1.370e-08 4.323e-09 3.170 0.00164 **
unemployment_rate 4.875e-04 1.127e-02 0.043 0.96553
share_college 2.565e-03 1.818e-03 1.411 0.15909
car_density 4.277e-04 3.351e-04 1.276 0.20254
w.gdp_in1000EUR 3.397e-08 1.107e-08 3.069 0.00230 **
w.unemployment_rate -2.848e-02 1.239e-02 -2.299 0.02203 *
w.share_college -4.753e-04 2.506e-03 -0.190 0.84966
w.car_density 1.038e-03 8.283e-04 1.254 0.21072
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2957 on 8770 degrees of freedom
Multiple R-squared(full model): 0.9602 Adjusted R-squared: 0.9582
Multiple R-squared(proj model): 0.02528 Adjusted R-squared: -0.0224
F-statistic(full model, *iid*):492.7 on 429 and 8770 DF, p-value: < 2.2e-16
F-statistic(proj model): 4.508 on 8 and 399 DF, p-value: 2.929e-05 - Estimate a twoways FE SAR panel model (use
spml())
Spatial panel fixed effects lag model
Call:
spml(formula = life_expectancy ~ gdp_in1000EUR + unemployment_rate +
share_college + car_density, data = inkar.df, index = c("Kennziffer",
"year"), listw = listw, model = "within", effect = "twoways",
lag = TRUE, spatial.error = "none")
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-1.569350 -0.164907 0.000625 0.167298 1.383741
Spatial autoregressive coefficient:
Estimate Std. Error t-value Pr(>|t|)
lambda 0.47997 0.01653 29.037 < 2.2e-16 ***
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
gdp_in1000EUR 1.2031e-08 1.4786e-09 8.1369 4.056e-16 ***
unemployment_rate -1.0767e-02 2.0558e-03 -5.2375 1.627e-07 ***
share_college 1.8501e-03 7.0611e-04 2.6202 0.008788 **
car_density 3.4915e-04 1.1950e-04 2.9218 0.003480 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1- Estimate the summary impacts.
Note that for some reason, the new version of impacts() in spatialreg looks for the attribute “have_factor_preds”, Which is not present in the splm object. So have to manually assign it via attr(sar.fe, "have_factor_preds") <- FALSE.
Impact measures (lag, trace):
Direct Indirect Total
gdp_in1000EUR dy/dx 1.236588e-08 1.076990e-08 2.313578e-08
unemployment_rate dy/dx -1.106695e-02 -9.638614e-03 -2.070556e-02
share_college dy/dx 1.901619e-03 1.656190e-03 3.557809e-03
car_density dy/dx 3.588594e-04 3.125439e-04 6.714033e-04
========================================================
Simulation results ( variance matrix):
========================================================
Simulated standard errors
Direct Indirect Total
gdp_in1000EUR dy/dx 1.498640e-09 1.501467e-09 2.922872e-09
unemployment_rate dy/dx 2.154812e-03 2.005993e-03 4.115034e-03
share_college dy/dx 7.372484e-04 6.622418e-04 1.395085e-03
car_density dy/dx 1.213255e-04 1.103715e-04 2.306613e-04
Simulated z-values:
Direct Indirect Total
gdp_in1000EUR dy/dx 8.352859 7.333305 8.049838
unemployment_rate dy/dx -5.059351 -4.781526 -4.980193
share_college dy/dx 2.457899 2.410438 2.443131
car_density dy/dx 3.020329 2.923211 2.987419
Simulated p-values:
Direct Indirect Total
gdp_in1000EUR dy/dx < 2.22e-16 2.2449e-13 8.8818e-16
unemployment_rate dy/dx 4.2068e-07 1.7397e-06 6.3521e-07
share_college dy/dx 0.013975 0.0159334 0.0145604
car_density dy/dx 0.002525 0.0034644 0.0028134